Robots.txt Là Gì? Hướng Dẫn Toàn Diện Từ Cơ Bản Đến Nâng Cao Cho SEO

Th6
Robots.txt là một tệp văn bản đơn giản được đặt tại thư mục gốc của website, có nhiệm vụ hướng dẫn các bot công cụ tìm kiếm (như Googlebot, Bingbot) cách thu thập dữ liệu trên trang web của bạn. Đây là một trong những yếu tố kỹ thuật quan trọng nhất trong SEO, giúp kiểm soát luồng crawl, bảo vệ nội dung nhạy cảm và tối ưu hóa ngân sách thu thập. Việc hiểu rõ robots.txt không chỉ giúp bạn tránh các lỗi phổ biến mà còn nâng cao hiệu quả SEO tổng thể.
Robots.txt Hoạt Động Như Thế Nào?
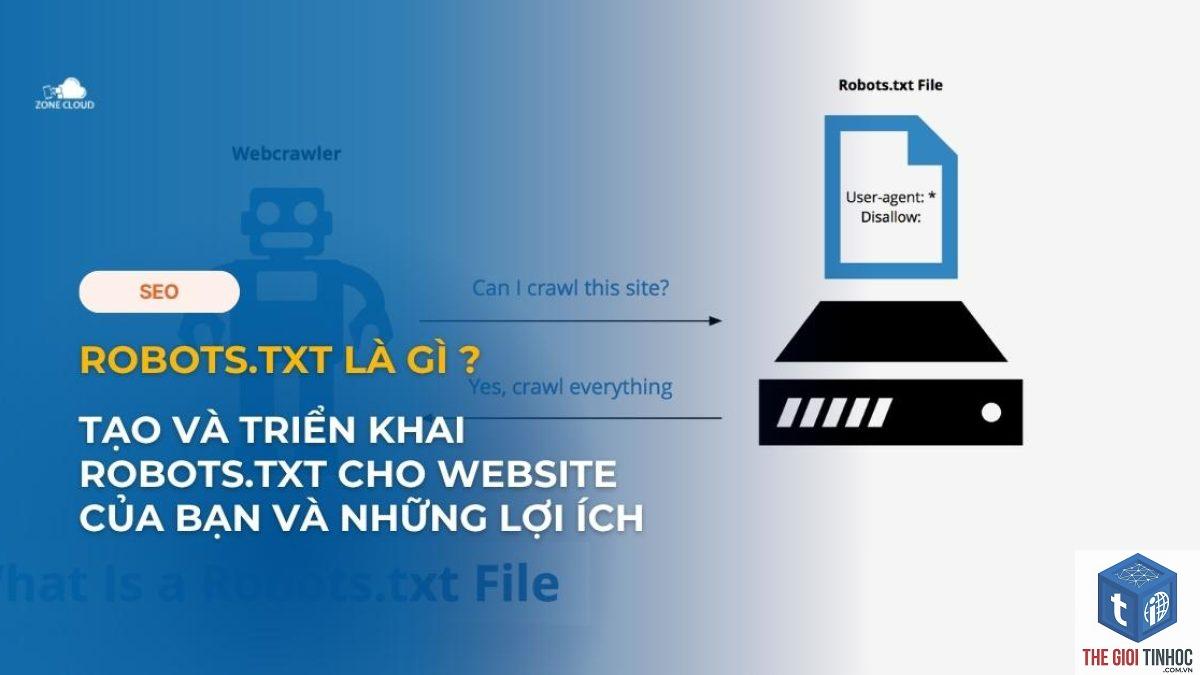
Khi một bot tìm kiếm truy cập vào website, nó sẽ tìm đến tệp robots.txt trước tiên. Tệp này chứa các chỉ thị dạng văn bản, được viết theo chuẩn Robots Exclusion Protocol (REP). Nếu bot tìm thấy tệp, nó sẽ đọc và tuân thủ các quy tắc được khai báo. Nếu không tìm thấy, bot sẽ tự do thu thập tất cả các URL có thể truy cập.
Quá trình diễn ra theo ba bước cơ bản:
- Bot gửi yêu cầu HTTP GET đến
https://tenmien.com/robots.txt. - Máy chủ trả về nội dung của tệp hoặc mã lỗi 404 nếu không tồn tại.
- Bot phân tích cú pháp và áp dụng các quy tắc trước khi bắt đầu crawl.
- User-agent: Xác định bot nào sẽ áp dụng quy tắc. Có thể dùng dấu
để áp dụng cho tất cả bot. - Disallow: Đường dẫn hoặc thư mục mà bot không được phép truy cập.
- Allow: Đường dẫn được phép truy cập, thường dùng để ghi đè lệnh Disallow.
- Sitemap: Đường dẫn tới sitemap XML của website (không bắt buộc nhưng hữu ích).
Cấu Trúc Chuẩn Của Tệp Robots.txt
Tệp robots.txt bao gồm các dòng chỉ thị, mỗi dòng mang một ý nghĩa riêng. Cú pháp cốt lõi gồm:
Ví Dụ Cụ Thể Về Robots.txt
User-agent: Disallow: /wp-admin/ Allow: /wp-admin/admin-ajax.php Sitemap: https://tenmien.com/sitemap.xml
Trong ví dụ trên, tất cả bot () đều bị chặn truy cập vào thư mục /wp-admin/, ngoại trừ file admin-ajax.php. Đồng thời, bot được thông báo vị trí sitemap để thu thập hiệu quả hơn.
Phân Loại Các Dạng Robots.txt Phổ Biến

Tùy vào mục đích sử dụng, robots.txt có thể được cấu hình theo nhiều dạng khác nhau:
| Loại | Mục đích | Ví dụ |
|---|---|---|
| Cho phép tất cả | Không chặn bất kỳ bot nào, thích hợp với trang tin tức. | User-agent: |
| Chặn toàn bộ | Ngăn mọi bot crawl, thường dùng khi website đang bảo trì hoặc là môi trường staging. | User-agent: |
| Chặn một phần | Chặn các thư mục hoặc file cụ thể không muốn hiển thị trên kết quả tìm kiếm. | User-agent: |
| Chặn bot cụ thể | Chỉ chặn một số bot như Googlebot, còn bot khác vẫn được phép. | User-agent: Googlebot |
Lợi Ích Khi Sử Dụng Robots.txt Đúng Cách
Việc thiết lập robots.txt mang lại nhiều lợi ích thiết thực cho chiến lược SEO:
- Tiết kiệm crawl budget: Ngăn bot lãng phí thời gian thu thập các trang không quan trọng như trang admin, trang lỗi, hoặc nội dung trùng lặp.
- Bảo vệ nội dung nhạy cảm: Chặn bot truy cập vào các thư mục chứa dữ liệu người dùng, file backup, hoặc nội dung chưa hoàn thiện.
- Giảm tải cho máy chủ: Khi bot không crawl các phần không cần thiết, tài nguyên máy chủ được giải phóng, cải thiện tốc độ tổng thể.
- Hướng dẫn bot ưu tiên: Bằng cách kết hợp với sitemap, bạn gián tiếp chỉ cho bot biết trang nào quan trọng cần được lập chỉ mục trước.
Hạn Chế Cần Biết Về Robots.txt

Không phải mọi thứ đều có thể kiểm soát qua robots.txt. Một số giới hạn đáng chú ý:
- Không phải lệnh bắt buộc tuyệt đối: Bot tuân thủ tự nguyện, bot độc hại hoàn toàn có thể bỏ qua.
- Không ngăn được lập chỉ mục: Nếu một trang bị chặn trong robots.txt nhưng vẫn có backlink, nó vẫn có thể hiển thị trên kết quả tìm kiếm dưới dạng URL rút gọn (không có snippet).
- Không bảo mật: File robots.txt là public, bất kỳ ai cũng có thể đọc được. Do đó, không nên dùng để ẩn nội dung quan trọng.
- Chỉ áp dụng cho crawl: Nó không ảnh hưởng đến index, muốn chặn index cần dùng thẻ meta robots noindex hoặc xóa URL khỏi sitemap.
So Sánh Robots.txt Với Các Phương Pháp Kiểm Soát Khác
| Phương pháp | Tác dụng | Phạm vi |
|---|---|---|
| Robots.txt | Ngăn bot crawl vào URL/thư mục. | Toàn bộ bot tuân thủ giao thức. |
| Meta robots noindex | Ngăn lập chỉ mục, nhưng bot vẫn có thể crawl. | Trang cụ thể, được đặt trong thẻ head HTML. |
| X-Robots-Tag | Kiểm soát index và crawl ở cấp độ HTTP header. | File không phải HTML (PDF, ảnh) hoặc toàn bộ URL. |
| .htaccess (Apache) | Chặn hoàn toàn truy cập từ người dùng và bot. | Duyệt web ở cấp máy chủ. |
Mỗi phương pháp có ưu nhược điểm riêng, và trong thực tế, bạn nên kết hợp robots.txt với meta robots noindex để kiểm soát chặt chẽ hơn.
Hướng Dẫn Tạo File Robots.txt Chuẩn SEO
Để tạo một file robots.txt hiệu quả, bạn cần tuân thủ các bước sau:
- Xác định danh sách URL cần chặn: Ví dụ: thư mục admin, thư mục cache, trang kết quả tìm kiếm nội bộ, thư mục plugin tạm thời.
- Xác định bot mục tiêu: Thường dùng
User-agent:cho tất cả, hoặc riêng Googlebot nếu muốn kiểm soát chi tiết. - Viết cú pháp rõ ràng: Mỗi lệnh trên một dòng. Không thêm khoảng trắng thừa.
- Thêm đường dẫn sitemap: Giúp bot phát hiện sitemap dễ dàng, đặc biệt quan trọng với website lớn.
- Kiểm tra bằng Google Search Console: Dùng công cụ Kiểm tra robots.txt để xác minh cú pháp và kết quả.
Ví Dụ File Robots.txt Hoàn Chỉnh
User-agent: Disallow: /cgi-bin/ Disallow: /wp-admin/ Disallow: /wp-content/plugins/ Disallow: /wp-content/themes/ Disallow: /search/ Disallow: /tag/?page= Disallow: /author/ Allow: /wp-admin/admin-ajax.php Sitemap: https://tenmien.com/sitemap_index.xml Sitemap: https://tenmien.com/post-sitemap.xml
Lưu ý rằng dấu đại diện cho mọi chuỗi ký tự, còn $ biểu thị kết thúc URL. Ví dụ: Disallow: /.pdf$ sẽ chặn mọi file PDF.
Những Sai Lầm Thường Gặp Khi Viết Robots.txt Và Cách Tránh
Rất nhiều webmaster mắc phải các lỗi cơ bản dẫn đến hậu quả nghiêm trọng cho SEO. Cách tránh: luôn dùng công cụ kiểm tra trước khi áp dụng.
Ứng Dụng Thực Tế Của Robots.txt Trong Các Loại Website Khác Nhau

Tùy vào loại website, cách sử dụng robots.txt có sự khác biệt:
- Website tin tức/blog: Thường cho phép tất cả bot, chỉ chặn các trang quản trị và trang tìm kiếm nội bộ. Đặt sitemap để bot crawl tin mới nhanh.
- Trang thương mại điện tử: Cần chặn các URL trùng lặp như bộ lọc sản phẩm, phân trang, tham số session. Đồng thời Allow các trang sản phẩm và danh mục chính.
- Website thành viên/diễn đàn: Chặn trang hồ sơ người dùng, trang đăng nhập, nội dung private. Có thể chặn bot trên toàn bộ khu vực yêu cầu đăng nhập.
- Trang staging hoặc phát triển: Chặn toàn bộ bot bằng
Disallow: /để tránh index nhầm, đồng thời thêm lệnh cho bot của riêng bạn nếu cần kiểm tra.
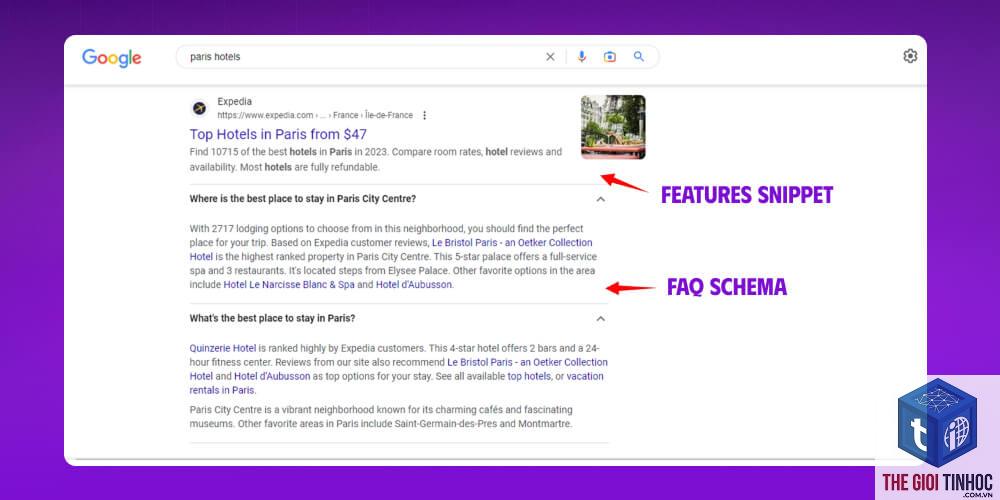
Câu Hỏi Thường Gặp Về Robots.txt (FAQ)
Robots.txt có bắt buộc phải có không?
Không. Nếu không có tệp robots.txt, bot sẽ tự động thu thập tất cả các URL công khai. Tuy nhiên, với website lớn hoặc có cấu trúc phức tạp, việc có robots.txt giúp tối ưu crawl và tránh lãng phí tài nguyên.
Robots.txt có ảnh hưởng đến thứ hạng tìm kiếm không?
Gián tiếp. Nếu bạn chặn nhầm các trang quan trọng, bot không crawl được thì trang đó không thể được lập chỉ mục, dẫn đến mất cơ hội xếp hạng. Ngược lại, sử dụng đúng cách giúp tập trung crawl vào nội dung chất lượng, cải thiện hiệu suất SEO tổng thể.
Có thể sử dụng wildcard và ký tự đại diện trong robots.txt không?
Có. Dấu đại diện cho bất kỳ chuỗi ký tự nào (ví dụ: /category/ chặn tất cả URL bắt đầu bằng /category/). Dấu $ khớp với kết thúc URL (ví dụ: /*.pdf$).
Làm thế nào để kiểm tra robot.txt có hoạt động đúng không?
Sử dụng Google Search Console: vào mục Thu thập dữ liệu > Kiểm tra robots.txt. Nhập URL muốn kiểm tra, công cụ sẽ cho biết URL đó có bị chặn bởi robots.txt hay không. Cũng có thể dùng các công cụ trực tuyến như robots-txt-validator.com.
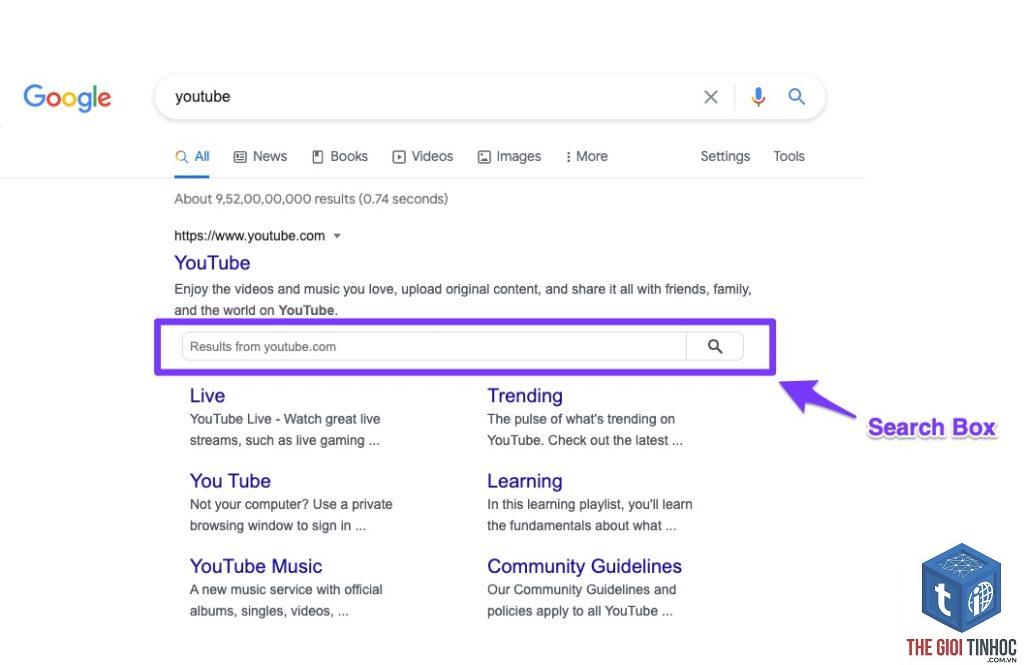
Có nên đặt nhiều sitemap trong robots.txt không?
Hoàn toàn nên. Bạn có thể khai báo nhiều dòng Sitemap: để chỉ dẫn bot đến nhiều sitemap khác nhau (ví dụ: sitemap bài viết, sitemap danh mục, sitemap hình ảnh).
Lưu Ý Quan Trọng Khi Làm Việc Với Robots.txt
Một vài điểm bạn cần ghi nhớ để tránh rủi ro:
- File robots.txt phải có tên chính xác là
robots.txt, viết thường, không dấu cách, đặt ở thư mục gốc (ví dụ:https://example.com/robots.txt). - Dung lượng tối đa của file thường là 500 KB, nhưng thực tế nên giữ dưới 32 KB để bot xử lý nhanh.
- Mỗi lần thay đổi, bot cần thời gian để nhận diện và áp dụng quy tắc mới (thường vài giờ đến vài ngày).
- Không sử dụng robots.txt để chặn các URL bạn muốn giữ bí mật. Thay vào đó, dùng xác thực HTTP hoặc.htaccess.
- Luôn backup file gốc trước khi chỉnh sửa, phòng trường hợp cần khôi phục nhanh.
Kết Luận
Robots.txt là một công cụ mạnh mẽ trong tay người làm SEO, giúp điều phối hoạt động của bot tìm kiếm một cách thông minh. Hiểu đúng về robots.txt không chỉ dừng lại ở việc biết cú pháp mà còn là nghệ thuật cân bằng giữa việc bảo vệ tài nguyên và tạo điều kiện cho nội dung chất lượng được lập chỉ mục. Để đạt hiệu quả tối ưu, hãy kết hợp robots.txt với các phương pháp kiểm soát khác như meta robots, sitemap, và thường xuyên kiểm tra qua Google Search Console. Một file robots.txt được viết tốt là nền tảng vững chắc cho chiến lược SEO bền vững.
- Crawl Depth Là Gì? – Hướng Dẫn Toàn Diện Để Google Index Nhanh và Sâu Hơn
- Video Search Filter Là Gì? Cách Tận Dụng Bộ Lọc Tìm Kiếm Video Hiệu Quả
- WordPress Post là gì? Hướng dẫn chi tiết từ A-Z cho người mới bắt đầu
- WordPress Permalink 404: Nguyên Nhân Và Cách Khắc Phục Toàn Diện
- WooCommerce PHP Lỗi: Nguyên Nhân, Cách Khắc Phục Toàn Diện Từ A-Z
Bài viết cùng chủ đề:
-

HowTo Schema Là Gì? Hướng Dẫn Chi Tiết Cách Triển Khai Schema Đánh Dấu Dạng Hướng Dẫn Để Tối Ưu SEO
-

Faqpage Schema Là Gì? Toàn Tập Chi Tiết Về Cấu Trúc Dữ Liệu Cho Trang FAQ
-

ImageObject Schema Là Gì? Hướng Dẫn Chi Tiết Cách Tối Ưu Hình Ảnh Cho SEO
-

VideoObject Schema là gì? Hướng dẫn chi tiết cách triển khai cho SEO Video
-
Aggregate Rating Schema Là Gì? Bí Quyết Tăng CTR Nhờ Đánh Giá Sao Chuẩn SEO
-

Review Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Để Tối Ưu Đánh Giá Sao Trên Google
-
Recipe Schema Là Gì? Hướng Dẫn Toàn Diện Đánh Bại Đối Thủ Trên Google Tìm Kiếm Ẩm Thực
-

JobPosting Schema là gì? Hướng dẫn chi tiết từ A-Z cho người làm tuyển dụng và SEO
-
Course Schema Là Gì? Toàn Tập Về Dữ Liệu Có Cấu Trúc Cho Khóa Học Từ A-Z
-

SoftwareApplication Schema Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho Website Ứng Dụng
-

Dataset Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Người Mới Bắt Đầu
-

Speakable Schema là gì? Hướng dẫn chi tiết giúp website của bạn được Google Assistant đọc to
-

Sitelinks Search Box Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Website Tìm Kiếm Thông Minh
-

SearchAction Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho SEO Chuyên Nghiệp
-

CollectionPage Schema Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho SEO
-
Webpage Schema Là Gì? Toàn Tập Chi Tiết Cho SEO Thành Công