Crawling là gì? Giải mã quy trình “thu thập dữ liệu” mà Google không muốn bạn hiểu sai
Th6
Crawling, hay còn gọi là quá trình “thu thập dữ liệu” hoặc “bò dữ liệu”, là một trong những khái niệm nền tảng và quan trọng nhất trong thế giới SEO và công nghệ tìm kiếm. Đây là bước đầu tiên và mang tính sống còn giúp các công cụ tìm kiếm như Google, Bing hay Yahoo khám phá và lập chỉ mục nội dung trên toàn bộ Internet. Nếu không có crawling, không một trang web nào có thể xuất hiện trên trang kết quả tìm kiếm. Vậy bản chất của crawling là gì, nó hoạt động ra sao và làm thế nào để tối ưu hóa quy trình này cho website của bạn? Bài viết dưới đây sẽ giải mã chi tiết từ khái niệm cốt lõi đến các ứng dụng thực chiến, giúp bạn làm chủ hoàn toàn kỹ thuật này.
Định nghĩa crawling và bản chất của quá trình thu thập dữ liệu

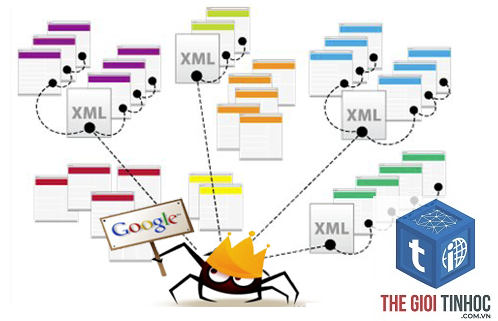
Crawling (web crawling) là quá trình tự động mà các công cụ tìm kiếm sử dụng các chương trình phần mềm gọi là “crawler” (hay “spider”, “bot”) để quét và thu thập thông tin từ hàng tỷ trang web trên Internet. Mục tiêu chính của việc này là khám phá các trang mới, cập nhật nội dung của các trang đã biết và thu thập dữ liệu để phục vụ cho bước lập chỉ mục (indexing) tiếp theo.
Hãy tưởng tượng Internet như một thư viện khổng lồ không có thủ thư. Các bot của Google sẽ đóng vai trò như những người đọc sách tự động, liên tục đi từ kệ sách này sang kệ sách khác, đọc nhan đề, mục lục và ghi chú lại nội dung chính. Quá trình này diễn ra 24/7, không ngừng nghỉ, với tốc độ xử lý lên đến hàng triệu trang web mỗi giây.
Về mặt kỹ thuật, một crawler bắt đầu bằng một danh sách các URL (seed URLs). Nó tải trang web này về, phân tích toàn bộ mã HTML, trích xuất tất cả các liên kết (hyperlinks) chứa trong đó, sau đó tiếp tục theo các liên kết đó để đến các trang mới. Vòng lặp này lặp đi lặp lại, tạo ra một mạng lưới khổng lồ, giống như một con nhện đang giăng tơ – đó cũng là lý do chúng được gọi là “spider” (con nhện).
Phân biệt giữa crawling và các khái niệm dễ nhầm lẫn
Rất nhiều người làm SEO mới thường nhầm lẫn crawling với indexing hoặc web scraping. Cần phải phân biệt rõ ràng ba khái niệm này để tránh sai lầm trong chiến lược tối ưu hóa.
Crawling vs Indexing
Crawling chỉ là bước “đi qua và lấy nội dung thô”. Indexing là bước tiếp theo, nơi công cụ tìm kiếm phân tích nội dung đã thu thập, sắp xếp và lưu trữ vào cơ sở dữ liệu khổng lồ của nó. Một trang web có thể được crawl nhưng chưa chắc đã được index. Crawling là phương tiện, indexing là đích đến.
Crawling vs Web Scraping
Web scraping là hành động trích xuất dữ liệu từ một trang web cụ thể một cách có chủ đích, thường phục vụ cho mục đích kinh doanh hoặc nghiên cứu. Trong khi đó, crawling mang tính tổng quát hơn, quét trên quy mô lớn để phục vụ cho việc xây dựng chỉ mục tìm kiếm. Một số người dùng có thể sử dụng crawling để thu thập dữ liệu của đối thủ cạnh tranh, nhưng mục đích chính của công cụ tìm kiếm là lập chỉ mục toàn bộ web.
| Tiêu chí | Crawling | Indexing | Web Scraping |
|---|---|---|---|
| Mục đích | Khám phá và thu thập URL | Phân tích và lưu trữ nội dung | Trích xuất dữ liệu cụ thể |
| Đầu ra | Danh sách URL và nội dung thô | Cơ sở dữ liệu có cấu trúc | File dữ liệu (CSV, JSON…) |
| Phạm vi | Toàn bộ web | Trang web đã được thu thập | Một hoặc một nhóm trang |
| Độ sâu | Nhiều lớp liên kết | Phân tích ngữ nghĩa nội dung | Thường chỉ một trang |
Quy trình hoạt động chi tiết của một web crawler

Để hiểu rõ hơn về crawling là gì trong thực tế, chúng ta cần nhìn vào từng bước cụ thể mà một bot như Googlebot thực hiện mỗi khi quét website của bạn.
Bước 1: Lấy danh sách URL khởi tạo
Mỗi crawler bắt đầu với một bộ các URL đã biết, thường là từ các sitemap XML, lịch sử crawl trước đó hoặc các dấu hiệu phát hiện trang mới từ mạng xã hội, backlink…
Bước 2: Gửi yêu cầu HTTP và tải trang
Bot gửi yêu cầu GET đến máy chủ web của bạn. Nó sẽ kiểm tra tệp robots.txt trước tiên để xem có bất kỳ quy tắc chặn nào không. Sau đó, nó tải toàn bộ nội dung HTML của trang về bộ nhớ đệm tạm thời.
Bước 3: Phân tích và trích xuất liên kết
Bot đọc mã nguồn HTML, xác định tất cả các thẻ (anchor tag) cùng với thuộc tính href. Nó cũng có thể phân tích các tài nguyên khác như hình ảnh, file CSS, JavaScript để hiểu rõ hơn về cấu trúc trang.
Bước 4: Xếp hàng các URL mới
Tất cả các liên kết tìm thấy được thêm vào hàng đợi (queue) để xử lý tiếp theo. Bot sẽ quyết định độ ưu tiên dựa trên các yếu tố như uy tín của trang nguồn, số lượng liên kết trùng lặp, tần suất cập nhật…
Bước 5: Lặp lại cho đến khi hoàn thành
Quá trình cứ thế tiếp diễn cho đến khi bot không tìm thấy thêm URL mới nào hoặc đã đạt đến giới hạn crawl budget của trang web (số lượng trang mà Google sẵn sàng crawl trong một khoảng thời gian).
Lợi ích của việc tối ưu hóa crawling cho SEO
Hiểu rõ và tối ưu hóa quá trình crawling mang lại những lợi ích trực tiếp cho thứ hạng và khả năng hiển thị của website.
- Phát hiện nội dung mới nhanh chóng: Khi bạn đăng bài viết mới, Googlebot sẽ nhanh chóng phát hiện và đưa vào chỉ mục, giúp nội dung xuất hiện trên kết quả tìm kiếm chỉ trong vài phút.
- Tiết kiệm ngân sách thu thập dữ liệu (crawl budget): Mỗi trang web có một lượng “ngân sách” crawl nhất định. Tối ưu hóa crawling giúp bot tập trung vào các trang quan trọng thay vì lãng phí vào trang lỗi hoặc trùng lặp.
- Giảm thiểu các trang mồ côi (orphan pages): Những trang không có bất kỳ liên kết nội bộ nào dẫn đến sẽ không được crawl. Tối ưu hóa cấu trúc liên kết giúp tất cả các trang quan trọng đều được khám phá.
- Cải thiện tốc độ lập chỉ mục: Một quy trình crawling mượt mà, không bị chặn bởi máy chủ chậm hay cấu hình sai, sẽ đẩy nhanh quá trình indexing.
- Googlebot: Bot chính của Google, dùng để thu thập dữ liệu cho tìm kiếm. Nó có phiên bản Desktop và Mobile riêng biệt.
- Bingbot: Bot của Microsoft Bing, hoạt động tương tự Googlebot nhưng có những quy tắc và ưu tiên riêng.
- Baiduspider: Bot của công cụ tìm kiếm Baidu (Trung Quốc), rất quan trọng nếu bạn nhắm đến thị trường Trung Quốc.
- Yandex Bot: Bot của công cụ tìm kiếm Yandex (Nga).
- DuckDuckBot: Bot của DuckDuckGo, một công cụ tìm kiếm tập trung vào quyền riêng tư.
- Facebook External Hit: Bot của Facebook dùng để lấy thông tin khi người dùng chia sẻ liên kết.
- Phân tích thị trường và đối thủ cạnh tranh: Các doanh nghiệp sử dụng crawling để thu thập giá sản phẩm, đánh giá khách hàng, mô tả hàng hóa từ các trang thương mại điện tử đối thủ.
- Nghiên cứu học thuật và khoa học dữ liệu: Các nhà nghiên cứu crawl các diễn đàn, mạng xã hội để thu thập dữ liệu lớn phục vụ phân tích tâm lý, xu hướng xã hội.
- Xây dựng cơ sở tri thức: Wikipedia và các dự án tương tự sử dụng crawling để thu thập và cập nhật thông tin từ nhiều nguồn khác nhau.
- Giám sát thương hiệu: Các công cụ như Mention hay Brand24 crawl toàn bộ web để phát hiện khi nào thương hiệu của bạn được nhắc đến.
- Google Search Console (GSC): Cung cấp báo cáo chi tiết về crawl stats, lỗi crawl, và cho phép gửi yêu cầu lập chỉ mục thủ công.
- Screaming Frog SEO Spider: Công cụ desktop mạnh mẽ cho phép bạn mô phỏng quá trình crawl của Googlebot trên website của mình, phát hiện liên kết hỏng, nội dung trùng lặp, vấn đề về redirect.
- Ahrefs Site Audit / SEMrush Site Audit: Các công cụ này có tính năng crawl tự động định kỳ, giúp phát hiện các vấn đề về SEO kỹ thuật liên quan đến crawl budget, robots.txt.
- DeepCrawl: Công cụ crawl chuyên nghiệp dành cho các doanh nghiệp lớn, cung cấp phân tích sâu về cấu trúc liên kết và luồng crawl.
- Sitebulb: Một lựa chọn thân thiện với người dùng, trực quan hóa dữ liệu crawl dưới dạng biểu đồ và báo cáo dễ hiểu.
Những yếu tố ảnh hưởng đến khả năng crawl của website

Không phải trang web nào cũng được crawl giống nhau. Google có những thuật toán riêng để quyết định mức độ ưu tiên crawl.
Tốc độ tải trang và hiệu suất máy chủ
Nếu máy chủ của bạn phản hồi chậm hoặc thường xuyên trả về lỗi 500, Googlebot sẽ giảm tần suất crawl để tránh gây quá tải. Thời gian phản hồi trung bình lý tưởng dưới 200ms.
Cấu trúc URL và kiến trúc thông tin
URL càng phẳng, càng dễ hiểu, bot càng dễ dàng theo dõi. Một cấu trúc depth quá sâu (nhiều thư mục con) sẽ khiến bot tốn nhiều bước để tiếp cận nội dung quan trọng.
Tệp robots.txt và thẻ meta robots
Đây là công cụ trực tiếp nhất để hướng dẫn bot. Nếu vô tình chặn các trang quan trọng trong robots.txt, chúng sẽ không bao giờ được crawl.
Sitemap XML
Sitemap hoạt động như một “bản đồ kho báu” cho Googlebot. Nó liệt kê tất cả các trang bạn muốn được lập chỉ mục, giúp bot không bỏ sót bất kỳ nội dung nào.
Chất lượng liên kết nội bộ
Liên kết nội bộ là con đường crawl chính. Mỗi trang nên có ít nhất một liên kết từ trang chủ hoặc các trang cấp cao khác. Số lượng liên kết lớn từ các trang uy tín sẽ thu hút bot đến thường xuyên hơn.
Các loại web crawler phổ biến hiện nay
Không chỉ có Googlebot, thế giới web crawling có rất nhiều bot khác nhau phục vụ các mục đích đa dạng.
Ứng dụng thực tế của crawling ngoài SEO

Mặc dù thường được nhắc đến trong SEO, crawling còn có nhiều ứng dụng rộng rãi trong các lĩnh vực khác.
Sai lầm thường gặp khi quản lý crawling và cách khắc phục
Ngay cả những SEOer có kinh nghiệm cũng mắc phải những lỗi phổ biến liên quan đến quá trình thu thập dữ liệu.
Chặn vô tình các trang quan trọng trong robots.txt
Lỗi kinh điển nhất là sử dụng “Disallow: /” để chặn toàn bộ trang web trong quá trình phát triển, sau đó quên không gỡ bỏ khi trang đã đi vào hoạt động. Cách khắc phục: luôn kiểm tra tệp robots.txt sau mỗi lần cập nhật, sử dụng công cụ Robots.txt Tester trong Google Search Console.
Sử dụng JavaScript không thể render
Googlebot có thể render JavaScript nhưng không phải lúc nào cũng hoàn hảo. Nếu nội dung quan trọng được load qua JavaScript mà không có fallback, bot sẽ không crawl được. Khắc phục bằng cách sử dụng server-side rendering hoặc dynamic rendering.
Trang bị trùng lặp nội dung
Crawl bot sẽ lãng phí tài nguyên nếu phải quét hàng trăm trang có nội dung giống hệt nhau chỉ khác tham số URL. Sử dụng thẻ canonical và tham số trong Google Search Console để hợp nhất chúng.
Ngân sách crawl bị lãng phí cho trang lỗi
Khi bạn xóa một trang mà không cài đặt redirect 301, bot sẽ tiếp tục cố gắng crawl trang đó, gây lãng phí. Hãy luôn redirect các trang đã xóa sang phiên bản mới nhất.
Các công cụ hỗ trợ quản lý và kiểm soát crawling

Để kiểm tra chính xác quá trình crawling trên website của mình, bạn cần sử dụng những công cụ chuyên dụng.
Câu hỏi thường gặp về crawling (FAQ)
Crawling diễn ra trong bao lâu?
Không có một khoảng thời gian cố định. Một website nhỏ có thể được crawl hoàn toàn trong vài phút, trong khi các website lớn như Amazon cần nhiều ngày. Tần suất crawl phụ thuộc vào độ uy tín, tần suất cập nhật nội dung và ngân sách crawl được cấp.
Làm sao để biết Google đã crawl website của tôi chưa?
Bản thân kỹ thuật không vi phạm pháp luật, nhưng việc sử dụng nó để thu thập dữ liệu vi phạm điều khoản dịch vụ của trang web hoặc thu thập thông tin cá nhân có thể dẫn đến hậu quả pháp lý. Luôn kiểm tra robots.txt và điều khoản sử dụng trước khi thực hiện.
Tại sao Googlebot chỉ crawl một số trang trên website của tôi?
Có ba lý do chính: 1) Trang bị chặn bởi robots.txt; 2) Trang không có liên kết nội bộ dẫn đến; 3) Ngân sách crawl của website bạn hạn chế do máy chủ chậm hoặc chất lượng nội dung thấp. Bạn cần kiểm tra tất cả các yếu tố này.
Nên chặn những trang nào trong robots.txt?
Bạn nên chặn các trang không mang lại giá trị tìm kiếm như: trang đăng nhập, trang quản trị, trang giỏ hàng, trang kết quả tìm kiếm nội bộ, file tĩnh không cần index (CSS, JS), và các trang chỉ dành cho mục đích nội bộ.
Kết luận: Làm chủ crawling để dẫn đầu cuộc chơi SEO
Crawling không phải là một thuật ngữ kỹ thuật khô khan xa vời, mà là một trong những yếu tố quyết định trực tiếp đến sự thành công của chiến lược SEO. Hiểu rõ crawling là gì và cách thức hoạt động của nó giúp bạn chủ động xây dựng một cấu trúc website thân thiện với bot, tối ưu hóa ngân sách thu thập dữ liệu và đảm bảo nội dung tốt nhất của bạn luôn được lập chỉ mục nhanh nhất.
Những chuyên gia SEO giỏi nhất không chỉ tập trung vào việc viết nội dung hay xây dựng backlink, mà họ còn dành thời gian để kiểm tra hàng ngày các chỉ số crawl trong Google Search Console, theo dõi log file của máy chủ và sử dụng các công cụ crawl chuyên sâu để phát hiện sớm các vấn đề. Hãy biến crawling từ một khái niệm trừu tượng thành một công cụ chiến lược trong tay bạn. Kiểm tra ngay cấu trúc liên kết nội bộ, tối ưu hóa robots.txt và đảm bảo sitemap XML của bạn được cập nhật – đó là những bước đầu tiên để biến quá trình thu thập dữ liệu thành lợi thế cạnh tranh bền vững cho website của bạn.
- Plugin WordPress không gỡ được: Nguyên nhân và cách xử lý triệt để
- Hướng dẫn chi tiết cách khôi phục plugin WordPress khi website gặp sự cố
- Cách sửa lỗi Plugin WordPress Update Download Failed nhanh chóng và triệt để
- WordPress wp-admin lỗi: Nguyên nhân và cách khắc phục triệt để
- Cách Khắc Phục Lỗi Elementor Save Failed Nhanh Chóng Và Hiệu Quả
Bài viết cùng chủ đề:
-

Crawl Trap Là Gì? Nguyên Nhân, Cách Nhận Biết Và Khắc Phục Hiệu Quả
-

Faceted Navigation Là Gì? Toàn Tập Chiến Lược Tối Ưu Cho Website Thương Mại Điện Tử
-

SEO Taxonomy là gì? Bí quyết tối ưu kiến trúc website để leo top Google
-

SEO Silo là gì? Bí quyết xây dựng cấu trúc website tối ưu thứ hạng từ khóa
-

Phân Tích Đối Thủ Cạnh Tranh (Competitor Analysis) Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho Chiến Lược Kinh Doanh Vượt Trội
-

Content Gap Analysis Là Gì? Cách Tận Dụng Khoảng Trống Nội Dung Để Bứt Phá Thứ Hạng SEO
-

Topical Map Là Gì? Hướng Dẫn Xây Dựng Bản Đồ Chủ Đề Chuẩn SEO 2025
-
Digital Footprint Là Gì? Toàn Bộ Sự Thật Về Dấu Chân Số Và Cách Kiểm Soát
-

Brand Entity Là Gì? Hướng Dẫn Toàn Diện Để Xây Dựng Thực Thể Thương Hiệu Mạnh
-

LLM Optimization Là Gì? Toàn Tập Chiến Lược Tối Ưu Mô Hình Ngôn Ngữ Lớn Từ A-Z
-

LLMO là gì? Toàn tập về vận hành và tối ưu hóa mô hình ngôn ngữ lớn
-

Geo SEO Là Gì? Giải Pháp Tối Ưu Tìm Kiếm Theo Vị Trí Địa Lý Toàn Diện Nhất
-

Answer Engine Optimization là gì? Hướng dẫn toàn diện để tối ưu cho công cụ trả lời AI
-

AI Overview Là Gì? Toàn Tập Về Tính Năng “Tóm Tắt AI” Của Google Đang Thay Đổi Ngành SEO
-
Search Generative Experience là gì? Hành trình thay đổi bộ mặt tìm kiếm của Google
-
Vector Search Là Gì? Giải Pháp Tìm Kiếm Thông Minh Cho Kỷ Nguyên Dữ Liệu Lớn