Vector Search Là Gì? Giải Pháp Tìm Kiếm Thông Minh Cho Kỷ Nguyên Dữ Liệu Lớn

Th6
Khi khối lượng dữ liệu số tăng lên chóng mặt, các phương pháp tìm kiếm truyền thống dựa trên từ khóa bắt đầu bộc lộ nhiều hạn chế. Người dùng không chỉ muốn tìm đúng từ, mà còn muốn tìm đúng ý nghĩa, đúng ngữ cảnh. Đó là lúc vector search nổi lên như một công nghệ cốt lõi thay đổi cách chúng ta truy xuất thông tin. Vậy chính xác thì vector search là gì, nó hoạt động ra sao và tại sao mọi doanh nghiệp từ thương mại điện tử đến chăm sóc sức khỏe đều đang chạy đua áp dụng?
Tìm Hiểu Bản Chất Của Vector Search
Vector Search Không Chỉ Là Tìm Kiếm Bằng Từ Khóa
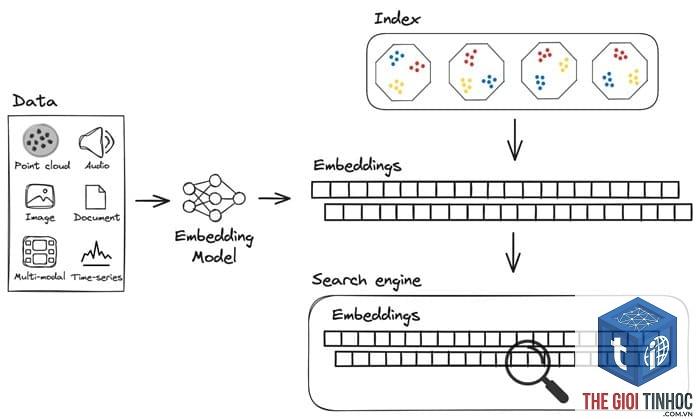
Vector search, hay tìm kiếm vector, là một kỹ thuật truy xuất thông tin dựa trên việc biểu diễn dữ liệu – văn bản, hình ảnh, âm thanh, video – dưới dạng các vector số trong không gian đa chiều. Thay vì so khớp chính xác ký tự, hệ thống tính toán khoảng cách hoặc độ tương đồng giữa vector truy vấn và vector của các đối tượng trong kho dữ liệu. Kết quả trả về là những mục có “ý nghĩa” gần nhất với truy vấn, dù chúng không chứa bất kỳ từ khóa khớp nào.
Để hiểu rõ hơn, hãy hình dung bạn đang tìm kiếm bức ảnh “một chú chó vàng chạy trên bãi cỏ”. Tìm kiếm từ khóa truyền thống sẽ chỉ trả về kết quả có chứa cụm từ này trong tên file hoặc thẻ alt. Trong khi đó, vector search hiểu rằng “chó vàng”, “golden retriever” và “chó săn mồi màu vàng” đều mô tả cùng một đối tượng, nhờ đó trả về kết quả chính xác hơn.
Nguyên Lý Hoạt Động Của Vector Search
Quá trình vector search gồm ba bước chính: embedding, indexing và searching. Ở bước embedding, dữ liệu thô được chuyển đổi thành vector số nhờ các mô hình học sâu như BERT, ResNet hay CLIP. Các vector này thường có từ 128 đến 4096 chiều. Bước indexing xây dựng cấu trúc dữ liệu đặc biệt (thường là ANN – Approximate Nearest Neighbor) để có thể tìm kiếm nhanh trên hàng tỷ vector. Cuối cùng, searching thực hiện so sánh vector truy vấn với tất cả các vector đã index để trả về top-k vector có độ tương đồng cao nhất.
| Phương pháp | Tìm kiếm từ khóa | Vector Search |
|---|---|---|
| Nguyên tắc | So khớp chính xác ký tự | So sánh độ tương đồng ngữ nghĩa |
| Kết quả | Phụ thuộc vào từ khóa đầu vào | Hiểu đúng ý định người dùng |
| Dữ liệu hỗ trợ | Văn bản thuần túy | Mọi loại dữ liệu (văn bản, ảnh, âm thanh) |
| Khả năng mở rộng | Hạn chế với dữ liệu phi cấu trúc | Mở rộng linh hoạt lên hàng tỷ mục |
Các Thành Phần Chính Trong Hệ Thống Vector Search
Embedding Models – Bộ Não Dịch Thuật Ngữ Nghĩa
Embedding model là trái tim của vector search. Các mô hình này học cách biểu diễn thế giới thực thành các con số có ý nghĩa. Ví dụ, mô hình Word2Vec có thể biến từ “vua” thành một vector gần với vector “hoàng đế” và xa hơn vector “cái bàn”. Ngày nay, các mô hình tiên tiến hơn như Sentence-BERT, OpenAI Embeddings, hoặc Cohere Embed cho phép tạo embedding cho toàn bộ câu hoặc đoạn văn, giữ nguyên sắc thái ngữ nghĩa phức tạp.
Vector Database – Kho Lưu Trữ Chuyên Dụng
Không phải cơ sở dữ liệu thông thường nào cũng xử lý tốt vector hàng nghìn chiều. Các vector database chuyên dụng như Pinecone, Weaviate, Qdrant, Milvus được thiết kế riêng để lưu trữ, đánh chỉ mục và truy vấn vector với tốc độ mili giây. Chúng hỗ trợ các thuật toán ANN như HNSW (Hierarchical Navigable Small World), IVF (Inverted File Index) hoặc PQ (Product Quantization) để giảm thời gian tìm kiếm từ O(n) xuống O(log n) hoặc nhanh hơn.
Similarity Metrics – Thước Đo Khoảng Cách Ngữ Nghĩa
Để biết hai vector có gần nhau hay không, hệ thống sử dụng các phép đo độ tương đồng. Cosine similarity là phổ biến nhất, đo cosin góc giữa hai vector, giá trị từ -1 đến 1. Euclidean distance đo khoảng cách hình học tuyến tính. Dot product phù hợp với các vector đã chuẩn hóa. Việc chọn metric phù hợp phụ thuộc vào cách huấn luyện embedding model và bản chất dữ liệu.
Phân Loại Vector Search: Exact Search Và Approximate Search

Exact Nearest Neighbor (ENN)
ENN duyệt toàn bộ cơ sở dữ liệu để tìm ra K vector gần nhất với vector truy vấn. Độ chính xác là 100%, nhưng chi phí tính toán rất lớn với dữ liệu lớn. Phương pháp này chỉ khả thi khi kích thước dữ liệu dưới vài chục nghìn mục. Trong thực tế, ENN thường được dùng làm benchmark để đánh giá chất lượng các thuật toán xấp xỉ.
Approximate Nearest Neighbor (ANN)
ANN là lựa chọn thực tế cho hầu hết ứng dụng sản phẩm. Các thuật toán ANN đánh đổi một phần độ chính xác (thường 90–99%) để đạt tốc độ gấp hàng trăm lần so với ENN. HNSW, hiện là thuật toán phổ biến nhất, xây dựng đồ thị phân cấp nhiều tầng cho phép tìm kiếm nhanh từ tổng quát đến chi tiết. Thời gian truy vấn điển hình cho 1 triệu vector với HNSW chỉ khoảng 1–10 mili giây.
Lợi Ích Và Hạn Chế Của Vector Search
Lợi Ích Vượt Trội So Với Tìm Kiếm Truyền Thống
- Hiểu ngữ nghĩa: Vector search nắm bắt được ý nghĩa ẩn đằng sau từ ngữ, cho phép tìm kiếm đồng nghĩa, trái nghĩa và các mối quan hệ phức tạp.
- Hỗ trợ đa phương thức: Một hệ thống duy nhất có thể tìm kiếm đồng thời văn bản, hình ảnh và âm thanh, miễn là chúng được chuyển đổi về cùng không gian vector.
- Khả năng mở rộng: Vector database hiện đại có thể quản lý hàng tỷ vector với hiệu suất ổn định, mở ra cánh cửa cho các ứng dụng quy mô internet.
- Cá nhân hóa mạnh mẽ: Embedding có thể được tinh chỉnh theo hành vi người dùng, mang lại trải nghiệm tìm kiếm ngày càng chính xác hơn.
- Chi phí tính toán: Việc tạo embedding, đặc biệt với mô hình lớn, tiêu tốn tài nguyên GPU đáng kể.
- Độ chính xác không tuyệt đối: ANN có thể bỏ sót một số kết quả liên quan, gây ảnh hưởng không mong muốn trong các lĩnh vực yêu cầu độ chính xác cao như y tế.
- Khó diễn giải: Khác với tìm kiếm boolean, vector search là một “hộp đen”, khó giải thích tại sao một kết quả được xếp hạng cao.
- Phụ thuộc vào chất lượng embedding: Một mô hình embedding kém sẽ tạo ra vector nhiễu, làm giảm hiệu quả toàn bộ hệ thống.
Hạn Chế Cần Cân Nhắc
So Sánh Vector Search Với Các Công Nghệ Tìm Kiếm Khác
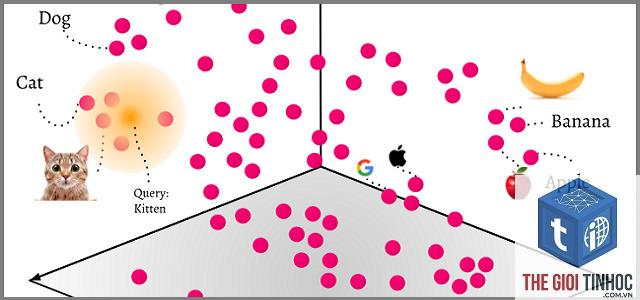
Vector Search vs. Full-text Search
Full-text search (Elasticsearch, Solr) dựa trên inverted index và TF-IDF/BM25 để khớp từ khóa. Nó vượt trội khi tìm kiếm chính xác một thuật ngữ, ví dụ “mã sản phẩm XYZ123”. Nhưng nếu người dùng gõ “điện thoại chụp ảnh đẹp”, full-text search sẽ ưu tiên các trang chứa chính xác từ “chụp ảnh đẹp”, bỏ qua các bài viết chất lượng về camera phone mà không có cụm từ đó. Vector search lấp đầy khoảng trống này bằng cách tìm kiếm theo ngữ nghĩa.
Vector Search vs. Semantic Search Truyền Thống
Semantic search thường được dùng để chỉ các hệ thống kết hợp nhiều kỹ thuật xử lý ngôn ngữ tự nhiên (NLP) như phân tích thực thể, nhận dạng ý định. Vector search là một công nghệ nền tảng cho semantic search hiện đại. Thực tế, các hệ thống sản phẩm mạnh nhất kết hợp cả full-text và vector search – gọi là hybrid search – để tận dụng ưu điểm của cả hai.
Ứng Dụng Thực Tế Của Vector Search Trong Doanh Nghiệp
Hệ Thống Gợi Ý Sản Phẩm Trong Thương Mại Điện Tử
Shopee, Lazada, Amazon sử dụng vector search để đề xuất sản phẩm dựa trên hành vi duyệt web. Khi người dùng xem một chiếc áo sơ mi trắng, embedding của áo được tạo ra và so sánh với embedding của hàng triệu sản phẩm khác. Kết quả trả về không chỉ áo sơ mi trắng tương tự mà còn có cả quần tây, giày da phù hợp phong cách, tạo trải nghiệm mua sắm liền mạch.
Chatbot Và Trợ Lý AI Hiểu Đúng Ý Người Dùng
Các chatbot như ChatGPT, Google Bard tích hợp vector search vào RAG (Retrieval-Augmented Generation). Khi người dùng hỏi về chính sách bảo hành, hệ thống không tìm kiếm nguyên văn câu hỏi mà truy xuất các đoạn văn bản liên quan đến bảo hành từ kho kiến thức doanh nghiệp, sau đó tổng hợp thành câu trả lời tự nhiên. Các công ty như Intercom, Zendesk đã áp dụng mô hình này để giảm 40% thời gian xử lý vé hỗ trợ.
Tìm Kiếm Hình Ảnh Và Video Trong Thời Gian Thực
Pinterest sử dụng vector search để triển khai tính năng “tìm kiếm bằng ảnh”. Một bức ảnh chụp chiếc ghế sofa được chuyển thành vector embedding, so sánh với cơ sở dữ liệu hàng tỷ hình ảnh để tìm ra các mẫu ghế tương tự về kiểu dáng, màu sắc, hoa văn. Pinterest cho biết hệ thống này đã tăng tỷ lệ tương tác người dùng lên 28% trong năm đầu triển khai.
Phát Hiện Gian Lận Và Bảo Mật
Trong lĩnh vực tài chính, vector search giúp phát hiện các giao dịch đáng ngờ tương tự nhau. Mỗi giao dịch được biểu diễn thành vector dựa trên các đặc điểm như địa điểm, thời gian, số tiền, thiết bị. Khi một giao dịch mới có vector gần với các giao dịch gian lận đã biết, hệ thống sẽ cảnh báo ngay lập tức. Visa đã áp dụng công nghệ này để giảm 25% tổn thất do gian lận.
Hướng Dẫn Triển Khai Vector Search Từ A Đến Z

Bước 1: Xác Định Dữ Liệu Và Lựa Chọn Embedding Model
Bắt đầu bằng việc xác định loại dữ liệu cần tìm kiếm. Dữ liệu văn bản tiếng Việt nên chọn các mô hình đa ngôn ngữ như paraphrase-multilingual-MiniLM-L12-v2 hoặc gọi API OpenAI text-embedding-3-small. Dữ liệu hình ảnh ưu tiên CLIP hoặc SigLIP. Dữ liệu âm thanh có thể dùng Wav2Vec 2.0 hoặc Whisper embeddings.
Bước 2: Xây Dựng Pipeline Embedding
Viết script xử lý dữ liệu thô, chia nhỏ thành các chunk phù hợp (thường 256–512 token). Pipe từng chunk qua embedding model, lưu kết quả cùng metadata vào vector database. Cần chú ý batch size để tối ưu thời gian và tránh lỗi memory.
Bước 3: Chọn Vector Database Và Cấu Hình Index
Với dự án nhỏ (dưới 100 nghìn vector), có thể dùng FAISS hoặc pgvector (extension của PostgreSQL). Dự án lớn hơn nên chọn Pinecone (managed service) hoặc Milvus (self-hosted). Cấu hình index: số chiều tương ứng với model, chọn metric cosine similarity cho hầu hết trường hợp, điều chỉnh tham số efConstruction và M nếu dùng HNSW.
Bước 4: Tối Ưu Truy Vấn Và Kết Quả
Thử nghiệm với giá trị K khác nhau (số kết quả trả về). Kết hợp reranking bằng model ngữ nghĩa nhẹ để tăng độ chính xác. Nếu dùng hybrid search, cân bằng trọng số giữa BM25 và vector score. Monitor latency thường xuyên – mục tiêu dưới 100ms cho ứng dụng real-time.
Sai Lầm Thường Gặp Khi Áp Dụng Vector Search
Chọn Model Embedding Không Phù Hợp Với Ngôn Ngữ Và Miền
Dùng model tiếng Anh cho dữ liệu tiếng Việt tạo ra embedding chất lượng kém, dẫn đến kết quả tìm kiếm sai lệch. Luôn kiểm tra bảng xếp hạng MTEB (Massive Text Embedding Benchmark) để chọn model phù hợp với ngôn ngữ và lĩnh vực cụ thể.
Bỏ Qua Tiền Xử Lý Dữ Liệu
Embedding model không thể xử lý tốt dữ liệu nhiễu, dấu câu lộn xộn, hoặc văn bản quá dài. Cần làm sạch dữ liệu, chuẩn hóa Unicode, loại bỏ ký tự đặc biệt trước khi tạo embedding. Với hình ảnh, cần crop và resize đúng kích thước đầu vào của model.
Cấu Hình Index Sai Dẫn Đến Hiệu Suất Thấp
Đặt efConstruction quá nhỏ khiến index kém chất lượng, tìm kiếm không chính xác. Hoặc đặt số lượng cluster trong IVF quá ít gây ra bottleneck truy vấn. Cần benchmark với dữ liệu thật để tìm tham số tối ưu, thay vì dùng mặc định.
Lưu Ý Quan Trọng Khi Sử Dụng Vector Search

Bảo mật dữ liệu là vấn đề then chốt. Vector embedding chứa thông tin ngữ nghĩa nhạy cảm, kẻ tấn công có thể suy ngược lại dữ liệu gốc từ vector. Do đó, cần mã hóa dữ liệu khi lưu trữ và khi truyền qua mạng. Các cloud vector database thường cung cấp encryption at rest và in transit.
Chi phí vận hành vector search không chỉ nằm ở dung lượng lưu trữ (mỗi vector float32 768 chiều chiếm ~3KB) mà còn ở tài nguyên tính toán cho embedding. Tính toán tổng chi phí ownership trước khi triển khai, bao gồm cả chi phí GPU cho model embedding nếu tự host.
Câu Hỏi Thường Gặp Về Vector Search
Vector search khác gì so với tìm kiếm bằng Elasticsearch?
Elasticsearch dựa trên inverted index và BM25, chỉ so khớp từ khóa. Vector search sử dụng embedding và độ tương đồng ngữ nghĩa. Hai công nghệ có thể kết hợp trong hybrid search để đạt kết quả tốt nhất.
Có cần GPU để chạy vector search không?
Chỉ cần GPU cho bước tạo embedding. Quá trình indexing và searching trên vector database hoàn toàn chạy trên CPU, trừ khi bạn tự build pipeline từ đầu với FAISS-GPU.
Vector search có thể áp dụng cho dữ liệu tiếng Việt không?
Hoàn toàn có thể. Các mô hình đa ngữ như Sentence-BERT multi-lingual, PhoBERT embedding, hoặc các API embedding từ Google, OpenAI đều hỗ trợ tiếng Việt tốt. Tuy nhiên cần fine-tune thêm nếu dữ liệu có thuật ngữ chuyên ngành.
Làm thế nào để đo độ chính xác của vector search?
Sử dụng recall@K – tỷ lệ kết quả đúng có trong top K, và precision@K – tỷ lệ kết quả đúng trong số kết quả trả về. So sánh với groundtruth được gán nhãn thủ công.
Khi nào không nên dùng vector search?
Khi dữ liệu hoàn toàn là cấu trúc (số, ngày tháng, mã code) và yêu cầu tìm kiếm chính xác tuyệt đối. Lúc này, tìm kiếm truyền thống hoặc cơ sở dữ liệu quan hệ vẫn là lựa chọn tối ưu.
Kết Luận
Vector search không chỉ là một công nghệ tìm kiếm mới, mà là nền tảng cho thế hệ ứng dụng AI hiểu được ngữ cảnh và ý định con người. Từ gợi ý sản phẩm, chatbot thông minh đến phát hiện gian lận, vector search đã chứng minh giá trị vượt trội trong hàng nghìn doanh nghiệp trên toàn cầu.
Để thành công với vector search, bạn không chỉ cần hiểu rõ vector search là gì, mà còn phải nắm vững quy trình chọn model, xây dựng index và tối ưu truy vấn. Bắt đầu với một dự án thử nghiệm nhỏ, sử dụng dữ liệu sạch và benchmark kỹ lưỡng, sau đó mở rộng dần. Trong kỷ nguyên dữ liệu phi cấu trúc bùng nổ, vector search chính là chìa khóa để biến dữ liệu vô hình thành giá trị hữu hình.
- Cách Khắc Phục Lỗi WordPress Login Timeout Dứt Điểm (2024)
- Plugin WordPress Uninstall Timeout: Nguyên Nhân, Cách Khắc Phục và Tối Ưu Hiệu Suất
- Entity SEO là gì? Hướng dẫn Toàn diện về Tối ưu Thực thể để Thống trị Bảng xếp hạng
- Google Freshness Là Gì? Bí Quyết Làm Mới Nội Dung Để Thống Trị Bảng Xếp Hạng
- Hướng dẫn chi tiết khắc phục mọi lỗi Elementor Product Widget cho người dùng WordPress
Bài viết cùng chủ đề:
-

HowTo Schema Là Gì? Hướng Dẫn Chi Tiết Cách Triển Khai Schema Đánh Dấu Dạng Hướng Dẫn Để Tối Ưu SEO
-

Faqpage Schema Là Gì? Toàn Tập Chi Tiết Về Cấu Trúc Dữ Liệu Cho Trang FAQ
-

ImageObject Schema Là Gì? Hướng Dẫn Chi Tiết Cách Tối Ưu Hình Ảnh Cho SEO
-

VideoObject Schema là gì? Hướng dẫn chi tiết cách triển khai cho SEO Video
-
Aggregate Rating Schema Là Gì? Bí Quyết Tăng CTR Nhờ Đánh Giá Sao Chuẩn SEO
-

Review Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Để Tối Ưu Đánh Giá Sao Trên Google
-
Recipe Schema Là Gì? Hướng Dẫn Toàn Diện Đánh Bại Đối Thủ Trên Google Tìm Kiếm Ẩm Thực
-

JobPosting Schema là gì? Hướng dẫn chi tiết từ A-Z cho người làm tuyển dụng và SEO
-
Course Schema Là Gì? Toàn Tập Về Dữ Liệu Có Cấu Trúc Cho Khóa Học Từ A-Z
-

SoftwareApplication Schema Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho Website Ứng Dụng
-

Dataset Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Người Mới Bắt Đầu
-

Speakable Schema là gì? Hướng dẫn chi tiết giúp website của bạn được Google Assistant đọc to
-

Sitelinks Search Box Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Website Tìm Kiếm Thông Minh
-

SearchAction Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho SEO Chuyên Nghiệp
-

CollectionPage Schema Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho SEO
-
Webpage Schema Là Gì? Toàn Tập Chi Tiết Cho SEO Thành Công