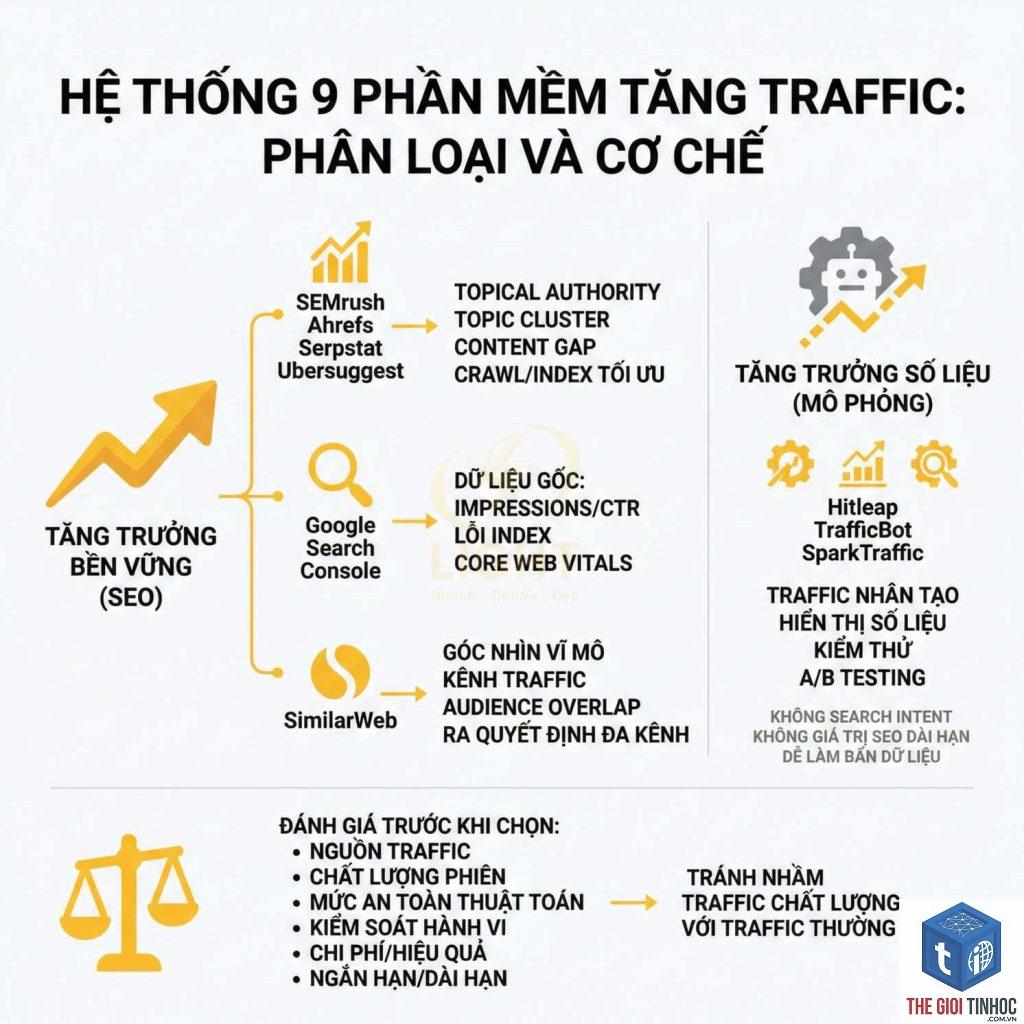
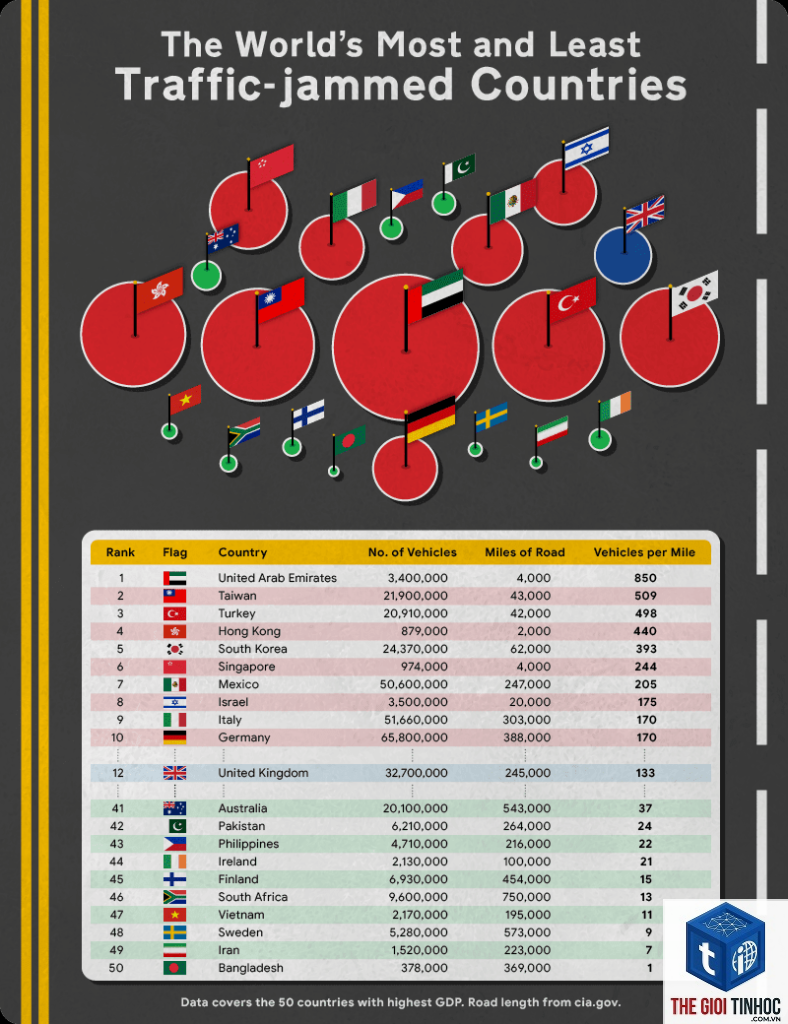
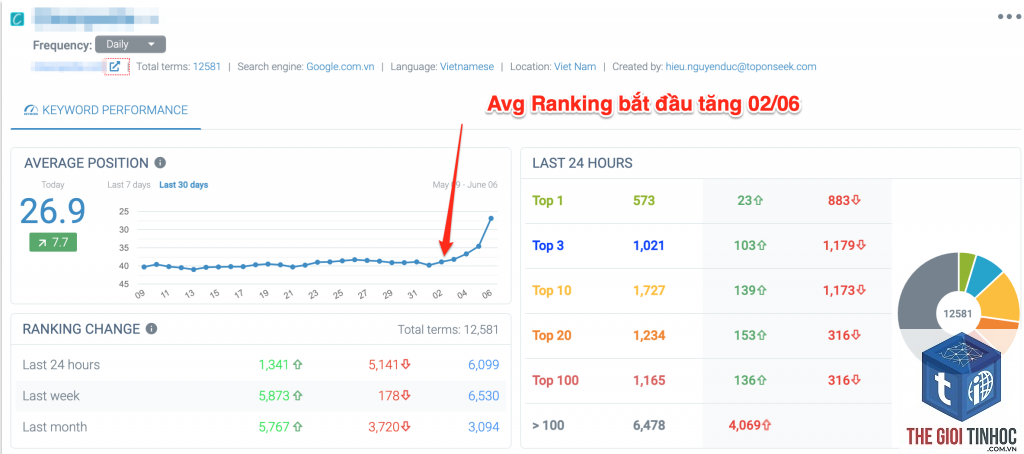
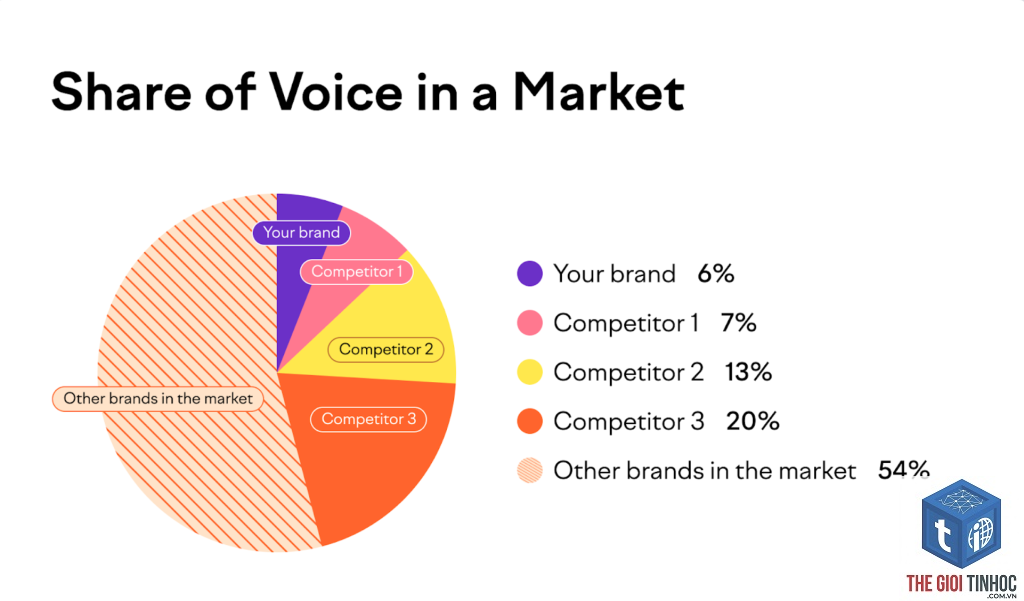
Log File Analysis Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho SEOer

Th6

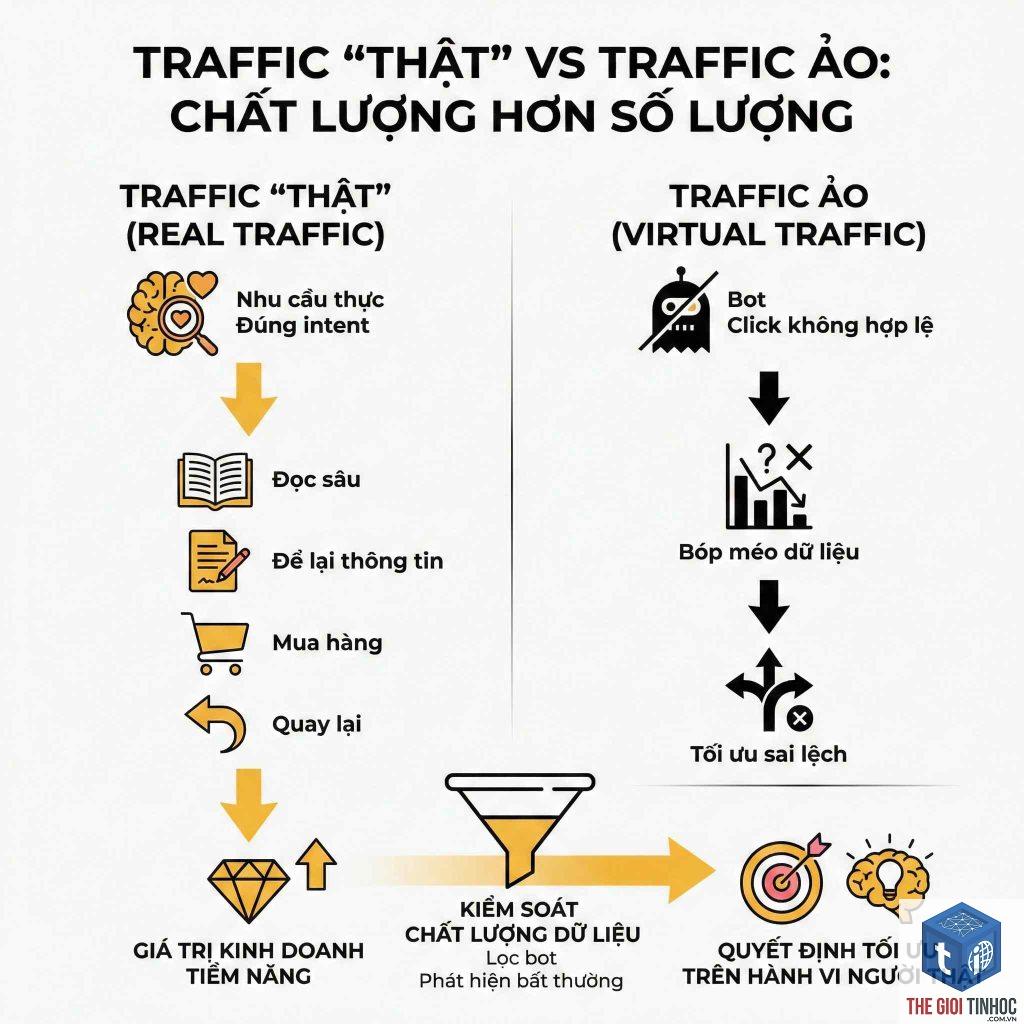
Log file analysis là quá trình đọc, xử lý và phân tích các tệp log (thường có đuôi.log hoặc.txt) được lưu trên máy chủ web. Mỗi dòng trong log ghi lại một yêu cầu HTTP với các thông tin như địa chỉ IP, thời gian, phương thức (GET/POST), đường dẫn URL, mã trạng thái (200, 404, 500…), kích thước file, và thông tin user-agent. Ví dụ: `192.168.1.1 – – [01/Jan/2025:12:00:00 +0000] “GET /trang-chu HTTP/1.1” 200 1234 “-” “Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)”` Dòng này cho thấy Googlebot đã truy cập URL `/trang-chu` lúc 12:00 và nhận mã 200 (thành công). Với hàng triệu dòng như vậy, việc phân tích thủ công gần như bất khả thi. Do đó, các công cụ chuyên dụng như Screaming Frog Log File Analyser, Botify, OnCrawl, hoặc Apache Logs Viewer được sử dụng để tổng hợp và trực quan hóa dữ liệu. Bản chất của log file analysis nằm ở tính chính xác và độ tin cậy. Vì dữ liệu được ghi trực tiếp từ máy chủ, không có bước trung gian, nó không bị ảnh hưởng bởi trình chặn quảng cáo, JavaScript không tải, hay cài đặt cookie. Điều này đặc biệt quan trọng khi bạn muốn đánh giá crawl budget – số lượng URL mà Googlebot có thể thu thập trong một khoảng thời gian nhất định.
Các loại log file thường gặp trong phân tích

Không phải mọi log file đều giống nhau. Đây là nguồn dữ liệu chính cho log file analysis vì nó chứa thông tin URL, mã trạng thái, và user-agent.
- Error Log: Ghi lại các lỗi máy chủ như 404 (Not Found), 500 (Internal Server Error), hoặc 403 (Forbidden). Phân tích error log giúp phát hiện trang bị lỗi, link hỏng, cấu hình sai.
- Agent Log: Tập trung vào thông tin user-agent (trình duyệt, bot). Mặc dù thông tin này thường nằm trong access log, một số máy chủ tách riêng để dễ dàng lọc bot.
Bảng dưới đây so sánh nhanh các loại log:
| Loại log | Mục đích chính | Thông tin quan trọng |
|---|---|---|
| Access Log | Ghi lại mọi request | URL, mã trạng thái, thời gian, IP, user-agent |
| Error Log | Ghi lại lỗi máy chủ | Mã lỗi, đường dẫn gây lỗi, nguyên nhân |
| Agent Log | Lọc bot / trình duyệt | User-agent, tần suất truy cập của từng bot |
Quy trình phân tích log file chi tiết

Để thực hiện log file analysis hiệu quả, bạn cần tuân theo một quy trình có cấu trúc. Thu thập log file từ máy chủ
Truy cập vào máy chủ qua FTP, SSH, hoặc panel quản trị (cPanel, Plesk). Log file thường nằm trong thư mục `/var/log/apache2/` (Apache) hoặc `/var/log/nginx/` (Nginx). Tải file có định dạng.log hoặc.gz (nén). Đảm bảo bạn có quyền đọc file.
2. Chuẩn bị và làm sạch dữ liệu
Xóa bỏ các dòng không cần thiết như request từ IP nội bộ, các bot không phải công cụ tìm kiếm (ví dụ bot của công cụ giám sát). Dùng lệnh grep để lọc chỉ giữ lại Googlebot, Bingbot. grep -i "Googlebot" access.log > googlebot.log
3. Sử dụng công cụ phân tích
Các công cụ phổ biến:
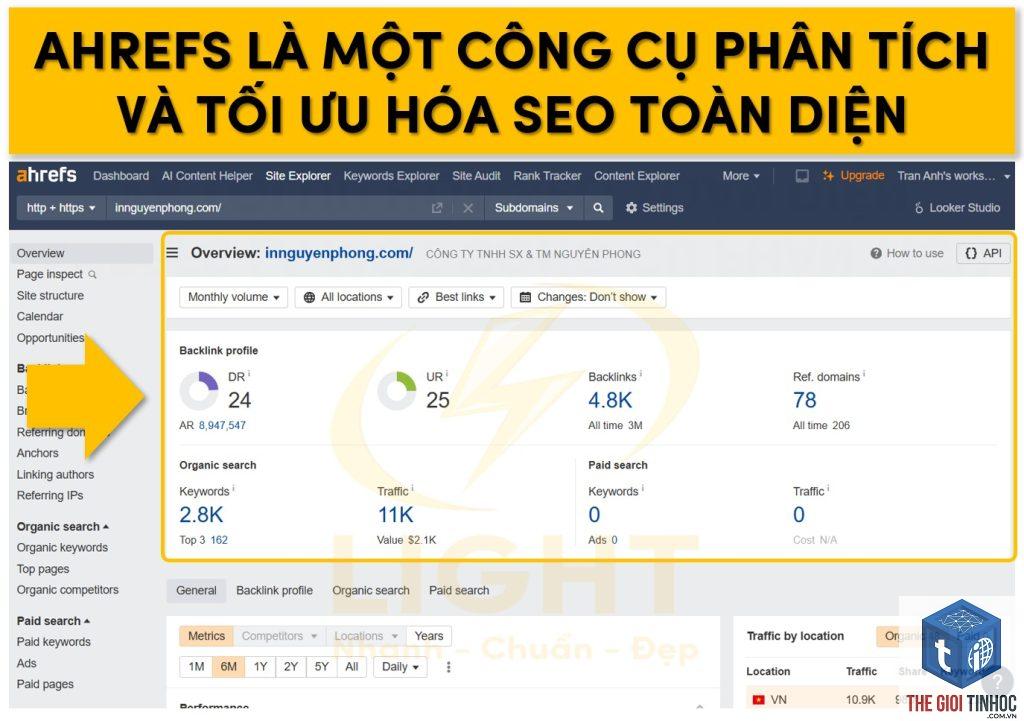
- Screaming Frog Log File Analyser: Miễn phí, dễ sử dụng, cho phép upload file log và trực quan hóa dữ liệu crawl.
- Botify: Phân tích chuyên sâu, kết hợp với dữ liệu crawl tự động.
- OnCrawl: Tích hợp nhiều nguồn dữ liệu, tốt cho SEO kỹ thuật.
- Python scripts: Dùng thư viện pandas để xử lý log file lớn, linh hoạt tùy chỉnh.
4. Phân tích và đưa ra insights
Sau khi có dữ liệu tổng hợp, tập trung vào các chỉ số:
- Crawl frequency: Googlebot truy cập URL nào nhiều nhất, URL nào ít hoặc không được truy cập.
- Status codes: Số lượng 200, 301, 404, 500. Quá nhiều 404 cho thấy link hỏng hoặc URL không tồn tại.
- Crawl budget: Tổng số request của Googlebot trong 1 ngày/tuần. Nếu vượt quá ngân sách, cần tối ưu.
- Bot vs user ratio: Tỷ lệ request từ bot so với người dùng, giúp đánh giá hiệu quả crawl.
5. Đề xuất hành động
Dựa trên phân tích, đưa ra các thay đổi cụ thể:
Lợi ích và hạn chế của log file analysis
Lợi ích vượt trội
- Dữ liệu chính xác tuyệt đối: Không bị ảnh hưởng bởi JavaScript, cookie, hay trình chặn quảng cáo.
- Phát hiện vấn đề crawl kịp thời: Ví dụ, Googlebot 404 trên trang quan trọng có thể được phát hiện trong vòng vài giờ thay vì chờ Search Console cập nhật.
- Tối ưu crawl budget: Biết chính xác bot dành thời gian cho URL nào, từ đó loại bỏ các URL “rác” khỏi chỉ mục.
- Kiểm tra hành vi của nhiều bot: So sánh Googlebot, Bingbot, Yandexbot, thậm chí cả bot AI.
- Phân tích lịch sử dài hạn: Log file lưu trữ từ nhiều tháng, cho phép so sánh xu hướng crawl theo thời gian.
Hạn chế cần lưu ý
- Dung lượng lớn: Website có triệu request mỗi ngày tạo ra log file hàng GB, khó xử lý thủ công.
- Yêu cầu kiến thức kỹ thuật: Cần hiểu về máy chủ, lệnh Linux, và công cụ phân tích.
- Không thể nhận biết nội dung trang: Log chỉ cho biết URL được request, không hiển thị nội dung trang hay chất lượng.
- Bảo mật: Log file chứa IP người dùng, có thể vi phạm GDPR nếu không ẩn danh hóa.
- Bot không đại diện 100%: Một số bot có thể không tuân theo robots.txt hoặc bị chặn bởi tường lửa.
So sánh log file analysis với các phương pháp khác
| Phương pháp | Độ chính xác | Chi phí | Thời gian phát hiện vấn đề | Ứng dụng chính |
|---|---|---|---|---|
| Log file analysis | Cao nhất (dữ liệu gốc) | Thấp (công cụ miễn phí hoặc tự viết script) | Ngay lập tức | Crawl budget, lỗi kỹ thuật, hành vi bot |
| Google Search Console | Trung bình (dữ liệu đã xử lý, có độ trễ 1-2 ngày) | Miễn phí | Chậm (24-48 giờ) | Index, lỗi coverage, hiệu suất tìm kiếm |
| Google Analytics | Thấp (chỉ ghi user, không ghi bot, phụ thuộc JS) | Miễn phí | Chậm (có thể bị mất dữ liệu) | Hành vi người dùng, traffic, conversion |
| Web server logs (giám sát) | Cao (log thô) nhưng không có công cụ SEO | Miễn phí (log có sẵn) | Phụ thuộc vào thiết lập | Giám sát tài nguyên máy chủ |
Rõ ràng, log file analysis vượt trội trong việc theo dõi bot và phát hiện sự cố crawl. Tuy nhiên, nó không thể thay thế Search Console hay Analytics mà cần kết hợp để có cái nhìn toàn diện.
Ứng dụng thực tế trong SEO
Phát hiện lỗi crawl và tối ưu crawl budget
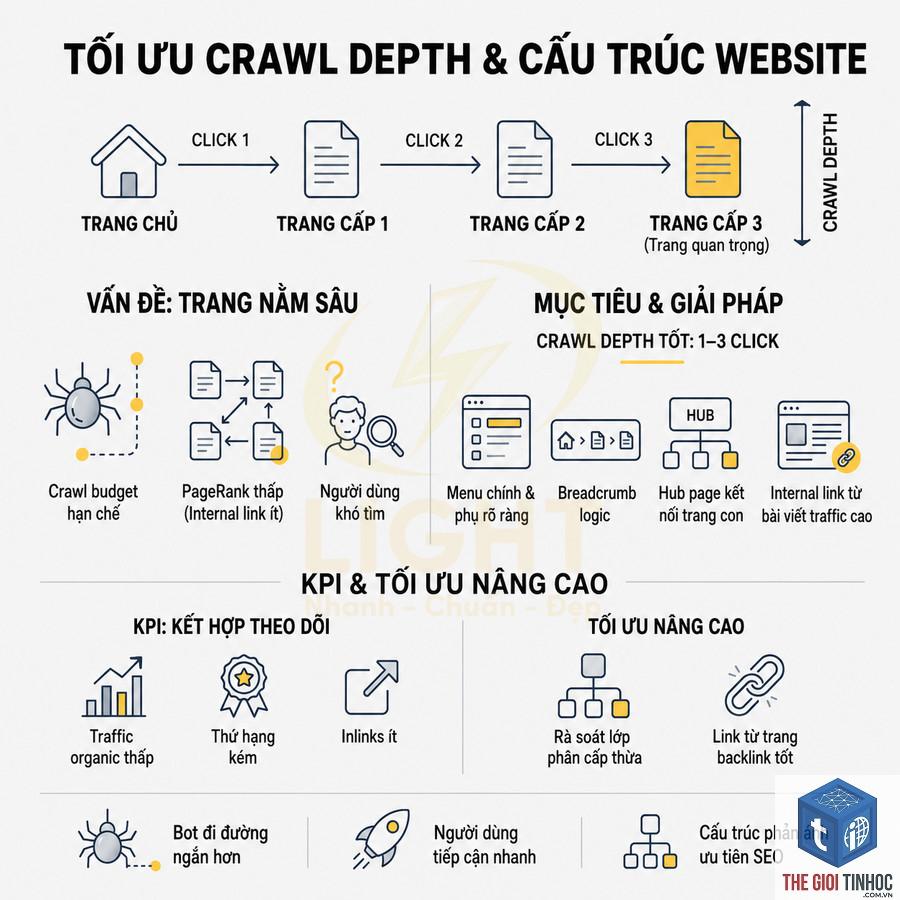
Một website thương mại điện tử với 50.000 sản phẩm có thể ghi nhận 1 triệu request từ Googlebot mỗi tuần. Bằng log file analysis, bạn thấy rằng 60% request trong số đó hướng đến các URL lọc sản phẩm (ví dụ /san-pham?mau=den&size=XL) – những URL có nội dung trùng lặp và ít giá trị. Kết quả là Googlebot lãng phí ngân sách, không đủ tài nguyên để crawl các trang sản phẩm chính. Giải pháp: chặn các tham số đó bằng robots.txt, thêm noindex, hoặc hợp nhất vào sitemap.
Phân tích hành vi Googlebot trên các trang mới
Khi bạn đăng bài viết mới, log file cho thấy Googlebot có ghé thăm ngay lập tức hay không. Nếu sau 3 ngày không có request từ Googlebot, có thể sitemap chưa được cập nhật, robots.txt chặn, hoặc máy chủ trả về 503. Phát hiện sớm giúp bạn push trang qua Search Console hoặc kiểm tra lại cấu hình.
So sánh crawl giữa các nhóm URL
Dùng log file để so sánh tần suất crawl giữa blog, trang danh mục, và trang sản phẩm. Nếu blog có 100 bài viết nhưng Googlebot chỉ crawl 10 bài mỗi tuần, trong khi trang danh mục có 50 URL lại được crawl 200 lần, bạn cần cân nhắc cấu trúc internal link hoặc điều chỉnh độ sâu.
Phát hiện bot giả mạo và tấn công
Log file cũng giúp nhận biết các user-agent lạ như “Mozilla/5.0 (compatible; Googlebot/2.1)” nhưng thực tế là bot từ Trung Quốc hoặc Nga. Bằng cách kiểm tra IP và hành vi (request quá nhanh, không tuân theo robots.txt),
Không hoàn toàn. Nếu website nhỏ (dưới 500 trang) và không gặp vấn đề về crawl,
Screaming Frog Log File Analyser có bản miễn phí giới hạn dung lượng log (khoảng 500MB). Ngoài ra,
Trong log file, lọc các dòng có user-agent chứa “Googlebot”. Công cụ log file analysis sẽ tự động phân loại và hiển thị danh sách URL kèm tần suất, mã trạng thái.
Việc đọc log file không ảnh hưởng đến hiệu suất máy chủ. Tuy nhiên, nếu bạn tải log file qua FTP hoặc SSH trong lúc máy chủ đang quá tải, có thể gây chậm nhẹ. Tốt nhất nên lên lịch tải log vào giờ thấp điểm.
Sự khác biệt giữa crawl frequency trong log file và Crawl Stats trong Search Console là gì?
Log file hiển thị số request thực tế từ Googlebot (cả request thành công và thất bại), trong khi Crawl Stats trong Search Console là dữ liệu tổng hợp sau khi Google đã xử lý, có thể bỏ qua một số request do giới hạn kỹ thuật. Log file thường chính xác và chi tiết hơn, nhưng Search Console dễ xem hơn.
Kết luận

Log file analysis là kỹ thuật không thể thiếu đối với SEOer chuyên sâu, đặc biệt khi làm việc với website lớn. Nó cung cấp dữ liệu thô, chính xác về hành vi của bot, giúp bạn phát hiện lỗi crawl, tối ưu ngân sách, và cải thiện hiệu suất SEO kỹ thuật. Dù có hạn chế về kích thước dữ liệu và yêu cầu kỹ thuật, nhưng lợi ích mang lại vượt xa chi phí đầu tư. Kết hợp log file analysis với Google Search Console, Google Analytics, và các công cụ crawl khác sẽ tạo nên một hệ thống giám sát SEO hoàn chỉnh. Hãy bắt đầu bằng cách thu thập log file từ máy chủ trong 7 ngày, dùng Screaming Frog để phân tích, và tập trung vào các URL có vấn đề. Chỉ cần vài giờ phân tích mỗi tuần, bạn có thể ngăn chặn những sự cố lớn trước khi chúng ảnh hưởng đến thứ hạng.
- Crawl Stats Report Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Để Tối Ưu Website
- Theme WordPress sau migrate website bị lỗi: Nguyên nhân và cách khắc phục toàn diện
- Plugin Form Không Lưu Dữ Liệu: Nguyên Nhân, Cách Khắc Phục và Giải Pháp Toàn Diện
- WordPress Hosting IOPS Limit: Tác Động Đến Hiệu Suất Website Và Cách Chọn Hosting Phù Hợp
- WooCommerce vs Custom Ecommerce: Lựa Chọn Nào Tối Ưu Cho Cửa Hàng Trực Tuyến Của Bạn?
Bài viết cùng chủ đề:
-

Device Breakdown Traffic Là Gì? Bí Quyết Phân Tích Lưu Lượng Theo Thiết Bị Để Tối Ưu SEO
-

Top Countries Traffic Là Gì? Bí Quyết Phân Tích Lưu Lượng Truy Cập Theo Quốc Gia Để Tối Ưu Chiến Lược SEO Toàn Cầu
-

Keyword Ranking Distribution Là Gì? Bí Quyết Phân Bổ Từ Khóa Để Thống Trị Bảng Xếp Hạng
-

Traffic Share Là Gì? Hướng Dẫn Toàn Diện Cách Phân Tích Thị Phần Traffic Để Tối Ưu Chiến Lược SEO
-

Share of Voice trong Ahrefs là gì? Hướng dẫn toàn diện từ A-Z để thống trị thị trường tìm kiếm
-
Traffic Estimation Là Gì? Hướng Dẫn Chi Tiết Cách Dự Báo Lưu Lượng Website Chính Xác
-

SEO Metrics là gì trong Ahrefs? Bí kíp đọc vị mọi chỉ số để làm chủ SEO
-
Domain Authority Comparison Là Gì? Hướng Dẫn Toàn Diện So Sánh Chỉ Số DA Từ A-Z
-

Disavow Suggestions Là Gì? Hướng Dẫn Chi Tiết Để Bảo Vệ Website Khỏi Backlink Xấu
-

Link Detox Là Gì? Hướng Dẫn Toàn Diện Để Lọc Sạch Hồ Sơ Backlink
-

Toxic Links trong Ahrefs Là Gì? Hướng Dẫn Toàn Diện Nhận Diện & Xử Lý Backlink Độc Hại
-

Link Velocity trong Ahrefs là gì? Cách tối ưu tốc độ tăng trưởng backlink để leo hạng nhanh
-
Backlink Growth Là Gì? Chiến Lược Tăng Trưởng Backlink Toàn Diện Cho SEO
-
Log File Analysis Ahrefs Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho SEO Chuyên Nghiệp
-

Orphan Pages Là Gì Trong Ahrefs? Cách Tìm Và Khắc Phục Triệt Để
-

Crawl Depth Trong Ahrefs Là Gì? Hướng Dẫn Toàn Diện Tối Ưu Chiến Lược Crawl Ngân Sách