Crawl Queue Là Gì? Cẩm Nang Toàn Diện Về Hàng Đợi Thu Thập Dữ Liệu Cho SEO

Th6
Giới Thiệu Về Crawl Queue Trong SEO

Khi nói đến quá trình thu thập dữ liệu của công cụ tìm kiếm, crawl queue là một khái niệm nền tảng mà bất kỳ SEOer nào cũng cần nắm vững. Crawl queue, hay còn gọi là hàng đợi thu thập dữ liệu, là cơ chế mà Googlebot và các bot tìm kiếm khác sử dụng để quản lý danh sách các URL cần được truy cập và phân tích. Nói một cách đơn giản, nó giống như một danh sách chờ, nơi các URL được xếp hàng và lần lượt được bot ghé thăm dựa trên một thứ tự ưu tiên nhất định.
Việc hiểu rõ crawl queue là gì giúp các chuyên SEO tối ưu hóa ngân sách thu thập dữ liệu, đảm bảo những trang quan trọng nhất được index nhanh chóng, đồng thời tránh lãng phí tài nguyên vào các trang chất lượng thấp. Đây là một trong những yếu tố cốt lõi ảnh hưởng trực tiếp đến hiệu suất SEO tổng thể của một website.
Bản Chất Và Cơ Chế Hoạt Động Của Crawl Queue

Định Nghĩa Chi Tiết Về Crawl Queue
Crawl queue là một cấu trúc dữ liệu dạng hàng đợi (queue) được vận hành bởi các thuật toán phức tạp của công cụ tìm kiếm. Mỗi khi bot tìm thấy một URL mới thông qua link từ trang khác, sitemap, hoặc các tín hiệu khác, URL đó được đưa vào hàng đợi. Tuy nhiên, không phải URL nào cũng được xếp cùng một vị trí. Thứ tự ưu tiên trong crawl queue được xác định dựa trên hàng loạt yếu tố như: thẩm quyền domain, tần suất cập nhật nội dung, độ sâu của trang, lịch sử thu thập và các tín hiệu từ người dùng.
Khi bot bắt đầu phiên thu thập, nó lấy URL đầu tiên từ hàng đợi, tải nội dung, phân tích và trích xuất các liên kết mới. Những liên kết này tiếp tục được thêm vào cuối hàng đợi (hoặc được ưu tiên nếu đáp ứng tiêu chí đặc biệt). Quá trình này lặp đi lặp lại cho đến khi hết thời gian thu thập hoặc hết URL trong hàng đợi trong phiên đó.
Thành Phần Chính Trong Hệ Thống Crawl Queue
- Bộ lập lịch (Scheduler): Quyết định thời điểm và tần suất thu thập từng URL dựa trên các tín hiệu ưu tiên.
- Bộ nhớ đệm (Cache): Lưu trữ tạm thời trạng thái của các URL đã thu thập để tránh trùng lặp.
- Cơ chế lọc trùng lặp (Deduplication): Đảm bảo cùng một URL không bị đưa vào queue nhiều lần.
- Hệ thống ưu tiên (Priority Engine): Phân tích các yếu tố như PageRank, freshness, user engagement để xếp hạng URL.
- Bộ điều khiển tốc độ (Rate Limiter): Kiểm soát tần suất truy cập để không gây quá tải cho máy chủ.
- Tối ưu ngân sách crawl: Biết cách sắp xếp ưu tiên giúp phân bổ tài nguyên thu thập vào đúng trang quan trọng.
- Cải thiện tốc độ index: Nội dung mới hoặc cập nhật được index nhanh hơn nếu biết cách kích hoạt tín hiệu ưu tiên.
- Giảm lãng phí: Tránh tình trạng bot thu thập quá nhiều trang chất lượng thấp, gây lãng phí ngân sách.
- Phát hiện lỗi kỹ thuật: Khi phân tích log file,
Crawl queue là danh sách các URL đang chờ được thu thập, còn crawl budget là tổng số lượng URL mà bot có thể thu thập trong một khung thời gian nhất định. Crawl queue chịu ảnh hưởng bởi thứ tự ưu tiên, còn crawl budget bị giới hạn bởi khả năng xử lý của server và tài nguyên của Google.
Làm sao để kiểm tra crawl queue của website tôi?
Bạn không thể xem trực tiếp crawl queue của Google, nhưng có thể gián tiếp thông qua log file server. Công cụ Google Search Console cung cấp báo cáo “Crawl Stats” cho biết số lượng URL được thu thập mỗi ngày, thời gian phản hồi trung bình và các lỗi gặp phải.
Có cách nào để đẩy nhanh một URL vào crawl queue không?
Có.
Nguyên nhân phổ biến bao gồm: URL bị chặn bởi robots.txt, có thẻ noindex, nội dung trùng lặp, bị lỗi server, hoặc nằm quá sâu trong cấu trúc website. Ngoài ra, nếu website có quá nhiều URL, một số trang có thể bị bỏ qua do ngân sách crawl có hạn.
Crawl queue có ảnh hưởng đến thứ hạng không?
Gián tiếp, có. Nếu một trang quan trọng không được thu thập kịp thời, nó sẽ không xuất hiện trong chỉ mục và do đó không thể xếp hạng. Crawl queue quyết định tốc độ index, nhưng thứ hạng phụ thuộc vào chất lượng nội dung, backlink và hàng trăm yếu tố khác.
Kết Luận
Crawl queue là một khái niệm kỹ thuật nhưng có tác động sâu sắc đến hiệu quả SEO tổng thể. Hiểu được cơ chế hoạt động, các yếu tố ảnh hưởng và cách tối ưu hàng đợi thu thập dữ liệu giúp bạn chủ động hơn trong việc đưa nội dung lên công cụ tìm kiếm. Không chỉ dừng lại ở việc biết “crawl queue là gì”, bạn cần thực hành bằng cách phân tích log file, tối ưu cấu trúc website và quản lý ngân sách crawl một cách thông minh.
Hãy nhớ rằng, Google không tiết lộ toàn bộ thuật toán crawl queue, nhưng những nguyên tắc được đề cập trong bài viết này đã được kiểm chứng qua nhiều năm thực tế. Áp dụng chúng một cách nhất quán sẽ giúp website của bạn được thu thập và index hiệu quả hơn, từ đó cải thiện thứ hạng và lưu lượng truy cập tự nhiên.
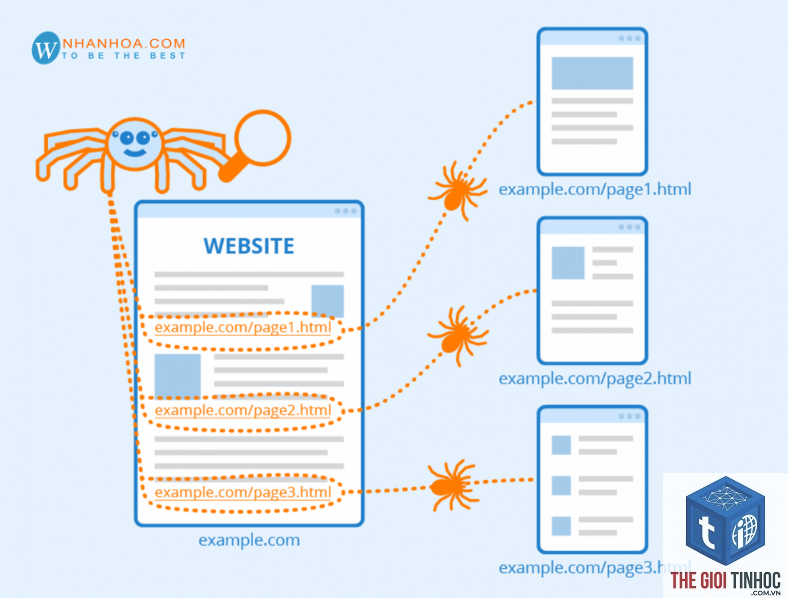
Quy Trình Thu Thập Dữ Liệu Qua Crawl Queue
Quy trình bắt đầu khi Googlebot nhận được tín hiệu về một URL từ nhiều nguồn khác nhau: liên kết từ trang web khác, sitemap XML gửi qua Google Search Console, hoặc URL được chia sẻ trên mạng xã hội. URL này được đưa vào crawl queue chính. Sau đó, bộ lập lịch sẽ xác định URL đó thuộc loại ưu tiên cao, thấp hay trung bình.
Khi đến lượt, bot sẽ gửi request HTTP đến máy chủ, tải toàn bộ nội dung HTML, CSS, JavaScript cần thiết. Nội dung sau đó được chuyển đến bộ phân tích để trích xuất văn bản, liên kết và metadata. Các liên kết nội bộ và liên kết ngoài mới được trích xuất sẽ tiếp tục được thêm vào crawl queue, nhưng với mức ưu tiên thấp hơn so với URL gốc. Điều này tạo thành một vòng lặp thu thập liên tục, được kiểm soát chặt chẽ để tối ưu hiệu suất.
Phân Loại Crawl Queue Dựa Trên Mức Độ Ưu Tiên
| Loại Queue | Mô Tả | Ví Dụ URL |
|---|---|---|
| Ưu tiên cao (High Priority) | URL mới được phát hiện từ trang chủ, trang danh mục chính, hoặc trang có nhiều backlink chất lượng. Được thu thập trong vòng vài phút đến vài giờ. | Trang chủ, bài viết mới được chia sẻ trên mạng xã hội lớn |
| Ưu tiên trung bình (Medium Priority) | URL từ sitemap, trang cập nhật định kỳ, hoặc trang có độ sâu từ 2-3 click. Thu thập trong vài ngày. | Trang sản phẩm mới, bài blog cập nhật hàng tuần |
| Ưu tiên thấp (Low Priority) | URL cũ, trang chất lượng thấp, trang không có liên kết nội bộ. Có thể mất nhiều tuần hoặc không bao giờ được thu thập lại. | Trang lỗi 404 cũ, trang có nội dung trùng lặp |
Yếu Tố Ảnh Hưởng Đến Thứ Tự Trong Crawl Queue

Thẩm Quyền Và Độ Tin Cậy Của Website (Domain Authority)
Các website có thẩm quyền cao, như các trang tin tức lớn hoặc thương hiệu uy tín, thường nhận được ưu tiên cao hơn trong crawl queue. Google ưu tiên thu thập các URL từ những domain đã được xác minh là cung cấp nội dung chất lượng và an toàn. Một domain mới với ít backlink sẽ phải chờ lâu hơn để URL của họ được xếp vào hàng đợi ưu tiên.
Tần Suất Cập Nhật Nội Dung (Content Freshness)
Các trang thường xuyên cập nhật nội dung mới hoặc có lịch sử thay đổi thường xuyên sẽ được bot ưu tiên thu thập lại. Điều này giải thích tại sao các trang tin tức, blog cập nhật hàng ngày lại được thu thập nhiều lần trong ngày. Ngược lại, các trang tĩnh không thay đổi trong nhiều tháng sẽ bị đẩy xuống cuối crawl queue.
Độ Sâu Của Trang (Crawl Depth)
Trang nằm càng gần trang chủ (ít click) thì càng có cơ hội được thu thập nhanh hơn. Một URL chỉ cách trang chủ 1-2 click thường được ưu tiên hơn so với URL nằm sâu 5-6 click. Đây là lý do các SEOer luôn khuyến khích xây dựng cấu trúc website phẳng với tối đa 3-4 click để đến bất kỳ trang nào.
Tín Hiệu Từ Người Dùng Và Mạng Xã Hội
Khi một URL được chia sẻ rộng rãi trên Facebook, Twitter, Reddit hoặc nhận được nhiều lượt truy cập từ người dùng thực, nó sẽ kích hoạt tín hiệu “hot” trong hệ thống crawl queue. Google có cơ chế phát hiện sự gia tăng đột biến về traffic và sẽ ưu tiên thu thập lại URL đó để cập nhật kết quả tìm kiếm.
Lợi Ích Của Việc Hiểu Rõ Crawl Queue

- Woocommerce Trang Sản Phẩm Lỗi: Nguyên Nhân, Cách Khắc Phục Toàn Diện Từ A-Z
- Theme WordPress Text Alignment Lỗi: Nguyên Nhân, Cách Khắc Phục Triệt Để
- WordPress có còn phổ biến không? Sự thật về vị thế của WordPress năm 2025
- Hướng dẫn toàn diện về Dynamic Text Elementor: Cách sử dụng và tối ưu nội dung động
- Theme WordPress Taxonomy Query Lỗi: Nguyên Nhân, Cách Khắc Phục và Tối Ưu Hiệu Suất
Bài viết cùng chủ đề:
-

HowTo Schema Là Gì? Hướng Dẫn Chi Tiết Cách Triển Khai Schema Đánh Dấu Dạng Hướng Dẫn Để Tối Ưu SEO
-

Faqpage Schema Là Gì? Toàn Tập Chi Tiết Về Cấu Trúc Dữ Liệu Cho Trang FAQ
-

ImageObject Schema Là Gì? Hướng Dẫn Chi Tiết Cách Tối Ưu Hình Ảnh Cho SEO
-

VideoObject Schema là gì? Hướng dẫn chi tiết cách triển khai cho SEO Video
-
Aggregate Rating Schema Là Gì? Bí Quyết Tăng CTR Nhờ Đánh Giá Sao Chuẩn SEO
-

Review Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Để Tối Ưu Đánh Giá Sao Trên Google
-
Recipe Schema Là Gì? Hướng Dẫn Toàn Diện Đánh Bại Đối Thủ Trên Google Tìm Kiếm Ẩm Thực
-

JobPosting Schema là gì? Hướng dẫn chi tiết từ A-Z cho người làm tuyển dụng và SEO
-
Course Schema Là Gì? Toàn Tập Về Dữ Liệu Có Cấu Trúc Cho Khóa Học Từ A-Z
-

SoftwareApplication Schema Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho Website Ứng Dụng
-

Dataset Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Người Mới Bắt Đầu
-

Speakable Schema là gì? Hướng dẫn chi tiết giúp website của bạn được Google Assistant đọc to
-

Sitelinks Search Box Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Website Tìm Kiếm Thông Minh
-

SearchAction Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho SEO Chuyên Nghiệp
-

CollectionPage Schema Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho SEO
-
Webpage Schema Là Gì? Toàn Tập Chi Tiết Cho SEO Thành Công