Information Retrieval Là Gì? Giải Mã Hệ Thống Tra Cứu Thông Tin Từ A Đến Z
Th6
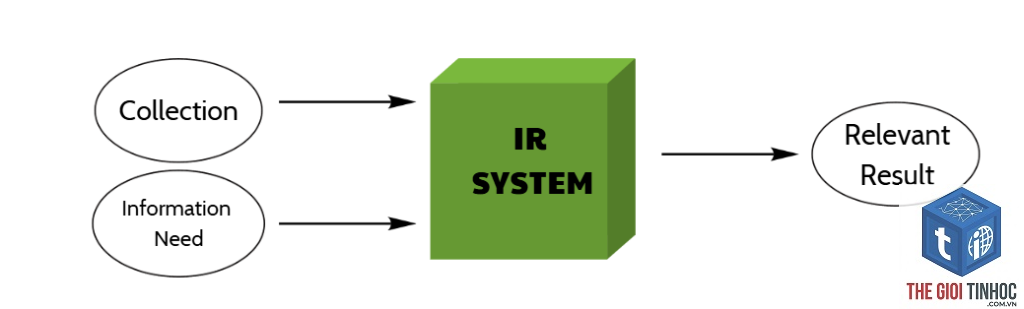
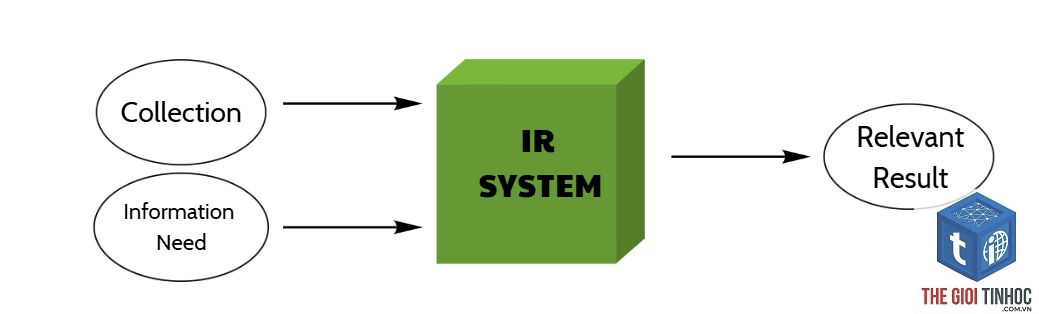
Trong thời đại bùng nổ dữ liệu, việc tìm kiếm thông tin chính xác giữa hàng tỷ trang web, tài liệu và cơ sở dữ liệu trở thành một thách thức lớn. Information retrieval là gì – câu hỏi tưởng chừng đơn giản nhưng lại là nền tảng của mọi công cụ tìm kiếm hiện đại. Information retrieval (IR) – tra cứu thông tin – là quá trình thu thập, tổ chức, lưu trữ và truy xuất thông tin từ một tập hợp tài liệu lớn dựa trên nhu cầu của người dùng. Khác với việc tìm kiếm đơn thuần trong một cơ sở dữ liệu có cấu trúc, IR xử lý dữ liệu phi cấu trúc như văn bản, hình ảnh, âm thanh, video. Hệ thống IR không chỉ đơn giản trả về kết quả khớp từ khóa, mà còn phải đánh giá mức độ liên quan, sắp xếp thứ tự ưu tiên và thích ứng với ngữ cảnh tìm kiếm. Google, Bing, hay thư viện số đều vận hành dựa trên nguyên lý cốt lõi của information retrieval.
Bản Chất Của Information Retrieval Và Sự Khác Biệt Với Database Query

Nhiều người thường nhầm lẫn giữa information retrieval và database query. Để hiểu rõ information retrieval là gì, cần phân biệt hai khái niệm này. Database query hoạt động trên dữ liệu có cấu trúc (bảng, cột, khóa) và yêu cầu truy vấn chính xác bằng ngôn ngữ SQL. Ngược lại, IR làm việc với dữ liệu phi cấu trúc hoặc bán cấu trúc, nơi người dùng có thể nhập câu hỏi bằng ngôn ngữ tự nhiên mà không cần biết cấu trúc dữ liệu.
Một hệ thống IR điển hình bao gồm các bước: thu thập tài liệu từ nhiều nguồn, xây dựng chỉ mục (index) ngược, xử lý truy vấn của người dùng qua các kỹ thuật như tokenization, stemming, loại bỏ stop words, sau đó đối sánh truy vấn với chỉ mục và xếp hạng kết quả dựa trên mô hình đánh giá độ tương tự. Cuối cùng, hệ thống hiển thị danh sách các tài liệu liên quan kèm đoạn trích (snippet) giúp người dùng nhanh chóng xác định thông tin cần thiết.
Các Thành Phần Cốt Lõi Của Hệ Thống Information Retrieval
Thu thập dữ liệu (Crawling)
Đây là giai đoạn đầu tiên, nơi hệ thống sử dụng các bot (crawler) để quét toàn bộ tài liệu trên web hoặc kho dữ liệu cục bộ. Các crawler theo dõi các liên kết, tải xuống nội dung, và gửi về kho lưu trữ thô. Tốc độ và khả năng mở rộng của crawler ảnh hưởng trực tiếp đến tính cập nhật của dữ liệu.
Xây dựng chỉ mục (Indexing)
Từ dữ liệu thô, hệ thống tạo ra một cấu trúc dữ liệu đặc biệt gọi là chỉ mục đảo (inverted index). Chỉ mục này lưu danh sách các thuật ngữ (term) cùng vị trí xuất hiện trong từng tài liệu. Ví dụ: từ “công nghệ” xuất hiện trong tài liệu A ở vị trí 5, tài liệu B ở vị trí 12. Nhờ chỉ mục, hệ thống có thể tìm kiếm hàng triệu tài liệu trong mili giây mà không cần quét toàn bộ nội dung.
Xử lý truy vấn (Query Processing)
Khi người dùng gõ “information retrieval là gì”, hệ thống sẽ thực hiện một loạt biến đổi: tách từ, chuẩn hóa chữ hoa/thường, loại bỏ từ vô nghĩa (like, the), chuyển từ về dạng gốc (stemming: “retrieval” -> “retrieve”). Quá trình này giúp truy vấn và tài liệu nằm cùng không gian biểu diễn, tăng khả năng khớp.
Đối sánh & Xếp hạng (Matching & Ranking)
Đây là trái tim của IR. Hệ thống tính toán độ tương tự giữa truy vấn và từng tài liệu trong chỉ mục. Các mô hình phổ biến gồm TF-IDF (Term Frequency-Inverse Document Frequency), BM25, và các mô hình ngữ nghĩa hiện đại dựa trên học sâu (neural IR) như BERT, Dense Passage Retrieval. Kết quả được sắp xếp theo điểm số (score) từ cao đến thấp và trả về cho người dùng.
Phân Loại Các Mô Hình Information Retrieval

Dựa trên cách thức biểu diễn và tính toán độ phù hợp, IR được chia thành ba nhóm chính:
| Mô hình | Đặc điểm | Ví dụ |
|---|---|---|
| Boolean Model | Sử dụng toán tử AND, OR, NOT. Kết quả là tập tài liệu thỏa chính xác điều kiện boolean, không có xếp hạng. | Thư viện số, hệ thống pháp lý |
| Vector Space Model | Biểu diễn truy vấn và tài liệu thành vector trong không gian nhiều chiều. Đo độ tương tự bằng cosine similarity. | Các máy tìm kiếm đầu tiên, Lucene |
| Probabilistic Model | Dựa trên lý thuyết xác suất. Ước lượng xác suất một tài liệu liên quan đến truy vấn. | BM25, Okapi BM25 |
| Neural IR | Sử dụng mạng nơ-ron học biểu diễn ngữ nghĩa sâu, vượt qua giới hạn khớp từ vựng. | Google BERT, ColBERT, DPR |
Các Chỉ Số Đánh Giá Chất Lượng Information Retrieval
Một hệ thống IR tốt cần đáp ứng hai tiêu chí cốt lõi: precision (độ chính xác) và recall (độ bao phủ). Nếu không hiểu information retrieval là gì ở khía cạnh đánh giá, khó có thể tối ưu được kết quả.
- Precision: Tỷ lệ tài liệu có liên quan trong số các tài liệu được trả về. Precision cao nghĩa là ít kết quả nhiễu.
- Recall: Tỷ lệ tài liệu liên quan được tìm thấy so với tổng số tài liệu liên quan trong toàn bộ kho. Recall cao nghĩa là ít bỏ sót thông tin.
- F1-Score: Trung bình điều hòa giữa Precision và Recall.
- MAP (Mean Average Precision): Trung bình precision tại mỗi vị trí tài liệu liên quan trong danh sách xếp hạng.
- NDCG (Normalized Discounted Cumulative Gain): Đánh giá chất lượng xếp hạng có trọng số theo thứ hạng, thích hợp khi mức độ liên quan có thang đo.
- Truy cập nhanh vào lượng thông tin khổng lồ mà không cần nhớ vị trí lưu trữ.
- Hỗ trợ tìm kiếm bằng ngôn ngữ tự nhiên, giúp người dùng không chuyên cũng dễ dàng sử dụng.
- Có khả năng mở rộng: từ vài nghìn tài liệu đến hàng tỷ trang web.
- Tích hợp xếp hạng thông minh, ưu tiên kết quả chất lượng cao hơn.
- Độ nhiễu (noise) cao: kết quả trả về có nhiều tài liệu không liên quan.
- Khó xử lý các truy vấn mơ hồ, đa nghĩa (polysemy) như “cầu” (cây cầu / mong cầu).
- Phụ thuộc vào chất lượng chỉ mục: nếu crawler bỏ sót hoặc chỉ mục lỗi, thông tin sẽ không xuất hiện.
- Chi phí tính toán lớn khi áp dụng các mô hình neural IR trên quy mô web.
- Chỉ dùng Boolean Model đơn thuần: Dễ dẫn đến kết quả quá cứng nhắc, bỏ sót tài liệu có liên quan nhưng không khớp chính xác từ ngữ.
- Không loại bỏ stop words: Các từ “và”, “của”, “là” xuất hiện quá nhiều, làm giảm tốc độ truy xuất và tăng nhiễu.
- Bỏ qua bước chuẩn hóa văn bản: Dữ liệu chưa tokenized, stemming hoặc loại bỏ emoji dẫn đến chỉ mục kém chất lượng.
- Chỉ đánh giá bằng precision: Nếu chỉ nhìn vào độ chính xác mà bỏ qua recall, hệ thống có thể đang bỏ lỡ nhiều tài liệu giá trị.
- Không cập nhật chỉ mục thường xuyên: Dữ liệu cũ dẫn đến kết quả lỗi thời, mất tin cậy.
Trong thực tế, hệ thống IR phải cân bằng giữa precision và recall tùy vào mục đích. Ví dụ: tra cứu y khoa ưu tiên recall cao để không bỏ sót bệnh lý, trong khi tìm kiếm thương mại ưu tiên precision để người dùng không bị ngợp.
Lợi Ích Và Hạn Chế Của Information Retrieval

Lợi ích
Hạn chế
So Sánh Information Retrieval Với Các Công Nghệ Liên Quan
| Tiêu chí | Information Retrieval | Database Query | Question Answering (QA) |
|---|---|---|---|
| Dữ liệu | Phi cấu trúc / bán cấu trúc | Cấu trúc (bảng, khóa) | Có thể là văn bản hoặc tri thức |
| Đầu vào | Câu tự nhiên hoặc từ khóa | SQL / cú pháp chính xác | Câu hỏi ngôn ngữ tự nhiên |
| Đầu ra | Danh sách tài liệu kèm snippet | Bảng dữ liệu chính xác | Câu trả lời cụ thể |
| Độ chính xác | Không tuyệt đối, dựa trên xếp hạng | Tuyệt đối (nếu truy vấn đúng) | Cao, thường là một đoạn ngắn |
| Ví dụ | Google, Elasticsearch | MySQL, Oracle | IBM Watson, ChatGPT search |
Ứng Dụng Thực Tế Của Information Retrieval Trong Đời Sống

Công cụ tìm kiếm web
Google, Bing, DuckDuckGo là những ứng dụng IR lớn nhất. Họ xử lý hàng tỷ truy vấn mỗi ngày bằng cách kết hợp chỉ mục khổng lồ với các thuật toán xếp hạng phức tạp như PageRank, RankBrain, MUM. Khi bạn tìm kiếm “information retrieval là gì”, Google hiểu ngữ cảnh, tìm kiếm tài liệu liên quan và hiển thị kết quả kèm trích đoạn nổi bật (featured snippet) – chính là định nghĩa bạn đang đọc.
Thư viện số và cơ sở dữ liệu học thuật
PubMed, IEEE Xplore, Google Scholar dùng IR để giúp nhà nghiên cứu tìm đúng bài báo giữa hàng triệu ấn phẩm. Các hệ thống này bổ sung metadata, từ khóa chuyên ngành và yếu tố trích dẫn để nâng cao độ chính xác.
Thương mại điện tử
Amazon, Shopee, Lazada ứng dụng IR để tìm kiếm sản phẩm. Truy vấn “áo thun nam cotton” được đối sánh với tiêu đề, mô tả sản phẩm, thậm chí cả đánh giá khách hàng để xếp hạng kết quả phù hợp nhất.
Tìm kiếm trong doanh nghiệp (Enterprise Search)
Các công ty lớn sử dụng Elasticsearch, Solr để xây dựng công cụ tìm kiếm nội bộ. Nhân viên có thể tìm kiếm tài liệu, email, hợp đồng từ kho dữ liệu phân tán chỉ bằng vài từ khóa.
Chatbot và Trợ lý ảo
Các chatbot hiện đại kết hợp IR với sinh văn bản (generation) để trả lời câu hỏi. Khi bạn hỏi “Lịch sử phát triển của information retrieval là gì?”, hệ thống truy xuất các đoạn tài liệu liên quan đến lịch sử IR, sau đó tổng hợp thành câu trả lời.
Sai Lầm Thường Gặp Khi Làm Việc Với Hệ Thống Information Retrieval
Lưu Ý Quan Trọng Khi Xây Dựng Hệ Thống Information Retrieval
Để thiết kế một hệ thống IR hiệu quả, cần tuân thủ các nguyên tắc sau. Thứ nhất, lựa chọn mô hình phù hợp với kiểu dữ liệu và tốc độ xử lý yêu cầu. Nếu cần tìm kiếm thời gian thực, Vector Space Model kết hợp với chỉ mục ngược là lựa chọn tối ưu. Thứ hai, đầu tư vào chất lượng tiền xử lý ngôn ngữ tự nhiên (NLP): xây dựng từ điển đồng nghĩa, xử lý lỗi chính tả, nhận diện thực thể. Thứ ba, liên tục đo lường hiệu suất bằng các chỉ số như MAP, NDCG và A/B testing trên người dùng thật.
Thứ tư, chú ý đến vấn đề bảo mật và quyền riêng tư. Trong môi trường doanh nghiệp, hệ thống IR phải phân quyền truy cập tài liệu, không để nhân viên tìm thấy file thuộc phòng ban khác. Cuối cùng, tận dụng phản hồi của người dùng (click-through, dwell time) để tinh chỉnh mô hình xếp hạng theo thời gian.
Câu Hỏi Thường Gặp (FAQ) Về Information Retrieval
Information retrieval khác gì với data mining?
Information retrieval tập trung vào truy xuất tài liệu liên quan đến truy vấn của người dùng. Data mining là quá trình khám phá pattern, xu hướng hoặc tri thức ẩn từ dữ liệu, không yêu cầu truy vấn cụ thể. IR trả lời “tìm tài liệu nào chứa thông tin tôi cần”, data mining trả lời “dữ liệu này đang nói lên điều gì”.
Những thách thức lớn nhất của information retrieval là gì?
Ba thách thức chính: (1) Semantic gap – khoảng cách giữa nghĩa truy vấn và nghĩa tài liệu, đặc biệt với từ đồng nghĩa, ẩn dụ; (2) Scale – xử lý hàng tỷ tài liệu trong mili giây; (3) Personalization – mỗi người có nhu cầu khác nhau, cùng một từ khóa cần kết quả khác nhau dựa trên lịch sử và ngữ cảnh.
Tại sao Google sử dụng nhiều thuật toán khác nhau cho IR?
Google kết hợp nhiều thuật toán để bù đắp điểm yếu của từng mô hình. PageRank dùng link graph để đánh giá uy tín, RankBrain dùng học máy để hiểu truy vấn lạ, BERT cải thiện khả năng hiểu ngữ cảnh. Sự kết hợp này giúp kết quả vừa chính xác vừa toàn diện.
Có thể tự xây dựng hệ thống IR cho website cá nhân không?
Có.
Dùng kỹ thuật query expansion: từ truy vấn gốc, mở rộng thêm từ đồng nghĩa hoặc từ liên quan (dùng word2vec hoặc thesaurus). Kết hợp với re-ranking: tăng precision ở top kết quả bằng mô hình ngữ nghĩa mạnh hơn.
Kết Luận
Information retrieval là gì – đó không chỉ là một câu hỏi định nghĩa, mà là cả một lĩnh vực khoa học và kỹ thuật đằng sau khả năng tìm kiếm thông tin của nhân loại. Từ những mô hình Boolean đơn giản đến các hệ thống neural IR hiện đại, IR đã thay đổi cách chúng ta tiếp cận dữ liệu, từ thư viện số đến tìm kiếm web toàn cầu. Hiểu được nguyên lý hoạt động, các mô hình, chỉ số đánh giá và ứng dụng thực tế sẽ giúp bạn không chỉ khai thác thông tin hiệu quả hơn, mà còn có thể xây dựng những hệ thống tìm kiếm thông minh cho riêng mình.
Trong một thế giới nơi dữ liệu ngày càng nhiều, việc nắm vững IR là chìa khóa để biến hỗn loạn thông tin thành tri thức có giá trị. Dù bạn là nhà phát triển, nhà nghiên cứu, hay người dùng hàng ngày, hãy bắt đầu bằng cách đặt câu hỏi đúng – và để hệ thống IR làm phần còn lại.
- Hướng Dẫn Toàn Diện Về Responsive Mode Elementor: Tối Ưu Giao Diện Cho Mọi Thiết Bị
- WordPress MySQL Overload: Nguyên Nhân, Dấu Hiệu Và Giải Pháp Tối Ưu Toàn Diện
- Plugin WordPress Không Kích Hoạt Được: Nguyên Nhân Và Cách Khắc Phục Chi Tiết
- Redirect Page Là Gì Trong GSC? Hướng Dẫn Chi Tiết Từ A-Z Cho SEO
- Robots.txt Là Gì? Hướng Dẫn Toàn Diện Từ Cơ Bản Đến Nâng Cao Cho SEO
Bài viết cùng chủ đề:
-

Search Console Insights Report Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho Người Mới
-

BigQuery Export Search Console Là Gì? Hướng Dẫn Toàn Diện Từ A Đến Z Cho SEO
-

Bulk Export GSC Là Gì? Hướng Dẫn Chi Tiết Xuất Dữ Liệu Hàng Loạt Từ Google Search Console
-

Export Data Search Console Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Để Tận Dụng Tối Đa Dữ Liệu
-

GSC API Là Gì? Hướng Dẫn Toàn Diện Từ A Đến Z Cho Người Làm SEO
-

Search Console API là gì? Hướng dẫn chi tiết từ A-Z cho SEO và Developer
-

Device Filter Là Gì? Hướng Dẫn Toàn Diện Về Bộ Lọc Thiết Bị Trong Marketing Và Bảo Mật
-
Country Filter Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Người Mới Bắt Đầu
-

Page Filter Là Gì? Hướng Dẫn Toàn Diện Từ Cơ Bản Đến Nâng Cao Cho Người Mới
-
Query Filter Là Gì? Hướng Dẫn Toàn Diện Từ Cơ Bản Đến Nâng Cao
-

Regex Filter Search Console Là Gì? Hướng Dẫn Chi Tiết Từ Cơ Bản Đến Nâng Cao Cho SEO Specialist
-
So sánh ngày trong Google Search Console (Compare Date) là gì? Hướng dẫn chi tiết A-Z cho người mới
-

Date Filter trong GSC là gì? Hướng dẫn chi tiết cách sử dụng bộ lọc ngày tháng trong Google Search Console
-

News Search Filter Là Gì? Hướng Dẫn Toàn Diện Về Bộ Lọc Tìm Kiếm Tin Tức Hiện Đại
-

Video Search Filter Là Gì? Cách Tận Dụng Bộ Lọc Tìm Kiếm Video Hiệu Quả
-

Image Search Filter là gì? Hướng dẫn Toàn Diện về Bộ Lọc Tìm Kiếm Hình Ảnh