Robots Blocked Pages Là Gì? Hướng Dẫn Toàn Diện Để Kiểm Soát Crawl Và Index

Th7
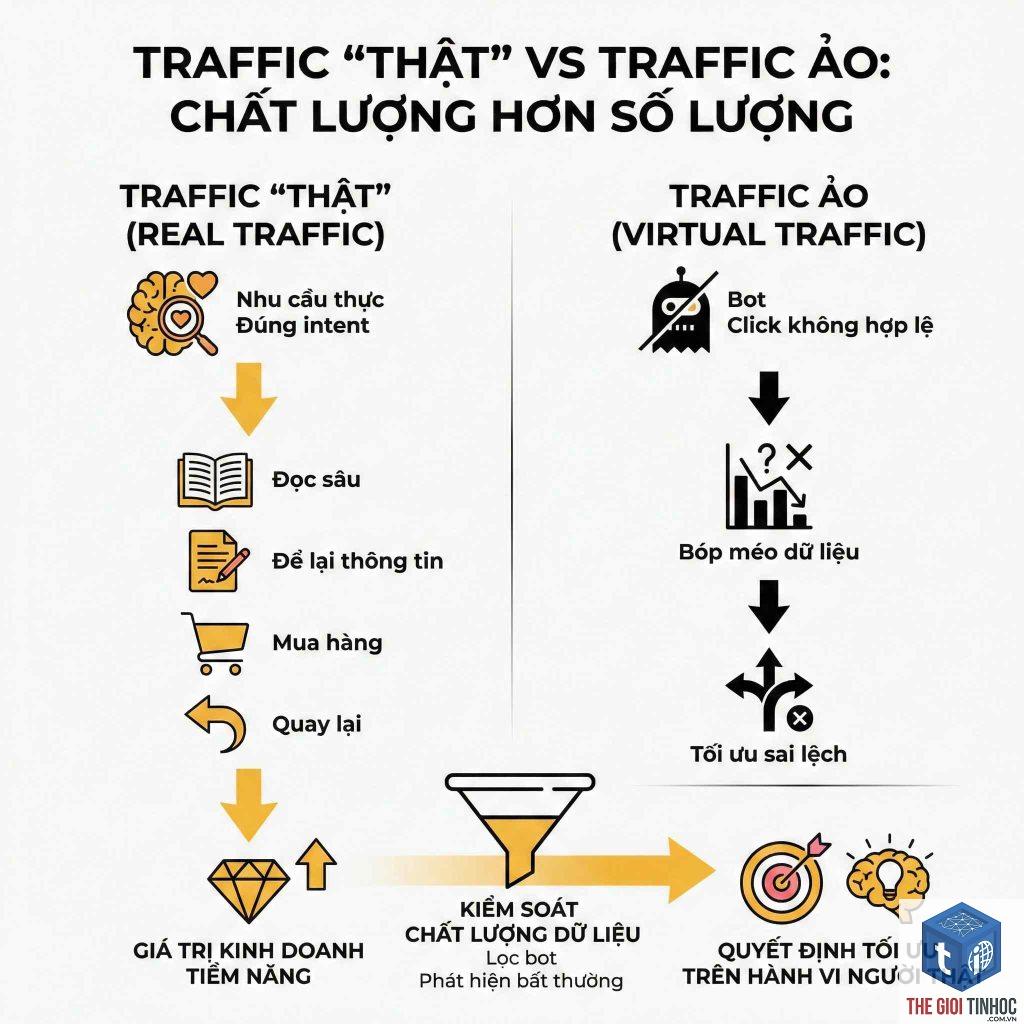
Trong thế giới SEO, việc quản lý cách công cụ tìm kiếm tương tác với website là yếu tố sống còn. Một trong những khái niệm quan trọng mà bất kỳ chuyên gia SEO nào cũng phải nắm vững chính là robots blocked pages. Vậy robots blocked pages là gì và nó ảnh hưởng thế nào đến thứ hạng của bạn? Đây không chỉ đơn thuần là những trang bị chặn bởi tệp robots.txt, mà còn có thể bao gồm các chỉ thị meta robots, header HTTP, hay thậm chí lỗi cấu hình từ plugin. Khi một trang bị chặn, Googlebot hoặc các bot khác sẽ không thể truy cập nội dung, dẫn đến việc trang đó không được lập chỉ mục hoặc không truyền được giá trị link juice. Bài viết này sẽ giải mã toàn bộ bí ẩn về robots blocked pages, từ định nghĩa cơ bản đến cách xử lý triệt để, giúp bạn tối ưu hóa ngân sách crawl và tránh những sai lầm chết người.
Robots Blocked Pages Là Gì? Định Nghĩa Và Bản Chất

Robots blocked pages (trang bị chặn bởi robot) là những trang web mà công cụ tìm kiếm không được phép truy cập hoặc lập chỉ mục do các chỉ thị từ chủ sở hữu site. Có hai cấp độ chặn: chặn ở cấp độ crawl (bot không thể đọc nội dung) và chặn ở cấp độ index (bot có thể đọc nhưng không đưa vào cơ sở dữ liệu).
Bản chất của việc này là dùng tệp robots.txt, thẻ meta robots, hoặc header X-Robots-Tag để hướng dẫn hành vi của bot. Nếu hiểu sai,
Ví dụ 1: Site thương mại điện tử
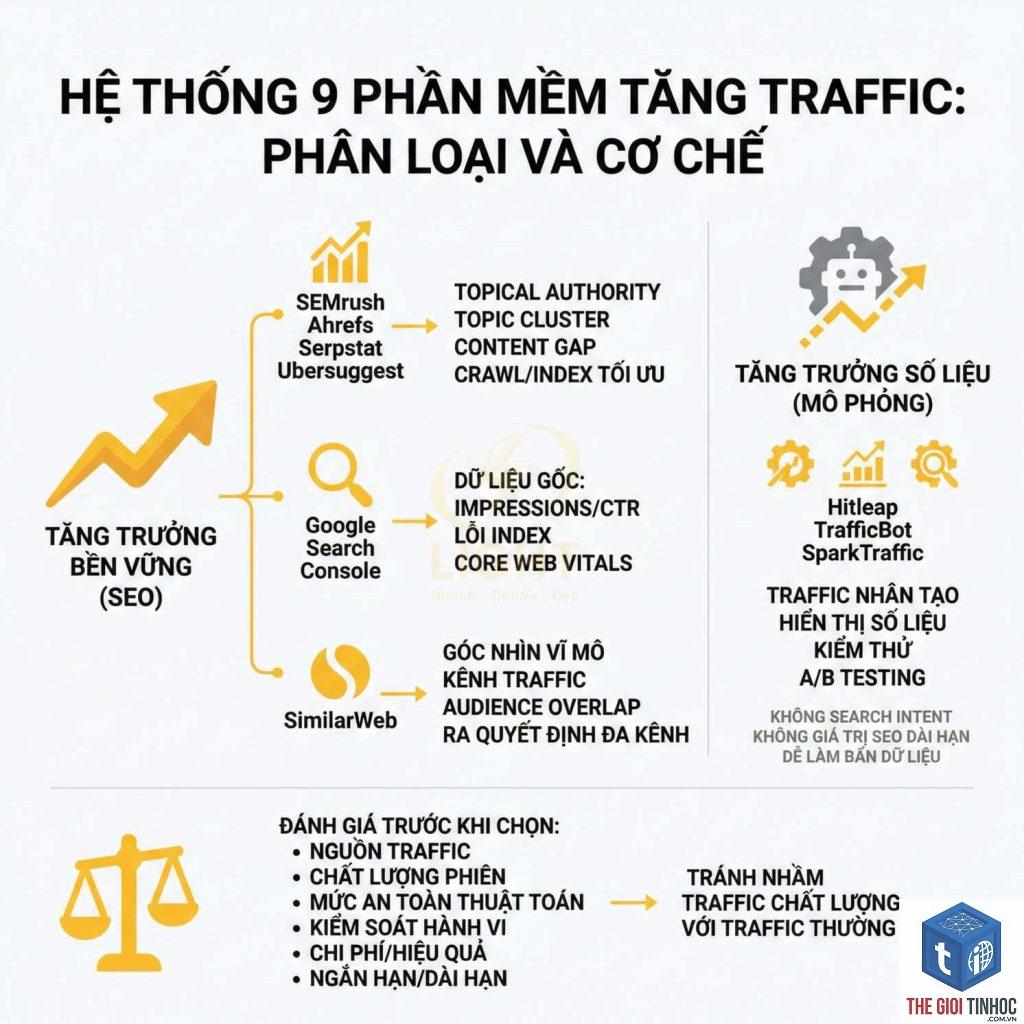
Một shop bán giày có hàng nghìn URL filter như: domain.com/giay?color=red&size=42. Các URL này tạo ra nội dung trùng lặp với trang category chính. Giải pháp: Chặn crawl tất cả URL có tham số query trong robots.txt bằng Disallow: /? và chỉ cho phép crawl các URL tĩnh. Điều này biến các trang filter thành robots blocked pages có chủ đích, giúp tập trung ngân sách crawl vào trang danh mục và sản phẩm chính.
Ví dụ 2: Trang quản trị
Các URL như /wp-admin/, /login, /cart đều là những trang không cần SEO. Chặn chúng trong robots.txt vừa an toàn vừa hiệu quả. Tuy nhiên, cần kiểm tra để tránh chặn cả file CSS/JS của admin, vì có thể ảnh hưởng đến khả năng hiểu trang của bot.
Ví dụ 3: Site tin tức với staging
Trong quá trình phát triển, site thường được đặt tại subdomain như staging.example.com. Bạn nên chặn toàn bộ staging trong robots.txt để tránh bị index nhầm. Và quan trọng: khi deploy lên production, hãy nhớ sửa lại file robots.txt cho production.
Lưu Ý Quan Trọng Khi Quản Lý Robots Blocked Pages
- Luôn đặt file robots.txt ở thư mục gốc, tên chính xác:
robots.txt(viết thường, không dấu). - Mỗi dòng trong robots.txt đều có ý nghĩa: thứ tự ưu tiên cần đúng cú pháp (Allow ghi đè Disallow trong cùng user-agent).
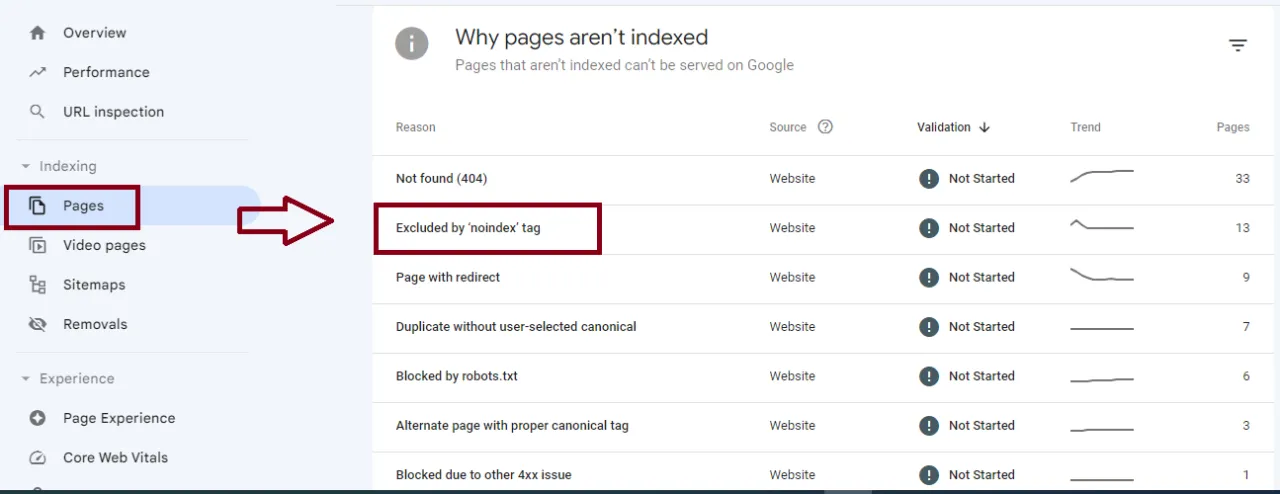
- Kiểm tra thường xuyên Google Search Console: mục Indexing > Pages để phát hiện sớm lỗi.
- Không chặn các file cần thiết cho render như CSS, JS, fonts nếu bạn muốn Google hiểu trang.
- Sử dụng robots.txt tester của Google hoặc các tool crawl để validate trước khi deploy thay đổi.
- Khi có thay đổi lớn về cấu trúc URL, hãy cập nhật sitemap và notify Google.
Câu Hỏi Thường Gặp Về Robots Blocked Pages
Robots blocked pages có được index không?
Thông thường không, vì bot không thể truy cập để đọc nội dung. Tuy nhiên, nếu có backlink mạnh từ nơi khác trỏ tới, Google vẫn có thể index URL đó dựa trên thông tin từ anchor text và các tín hiệu khác. Đây là hiện tượng hiếm, thường xảy ra khi trang bị chặn một phần.
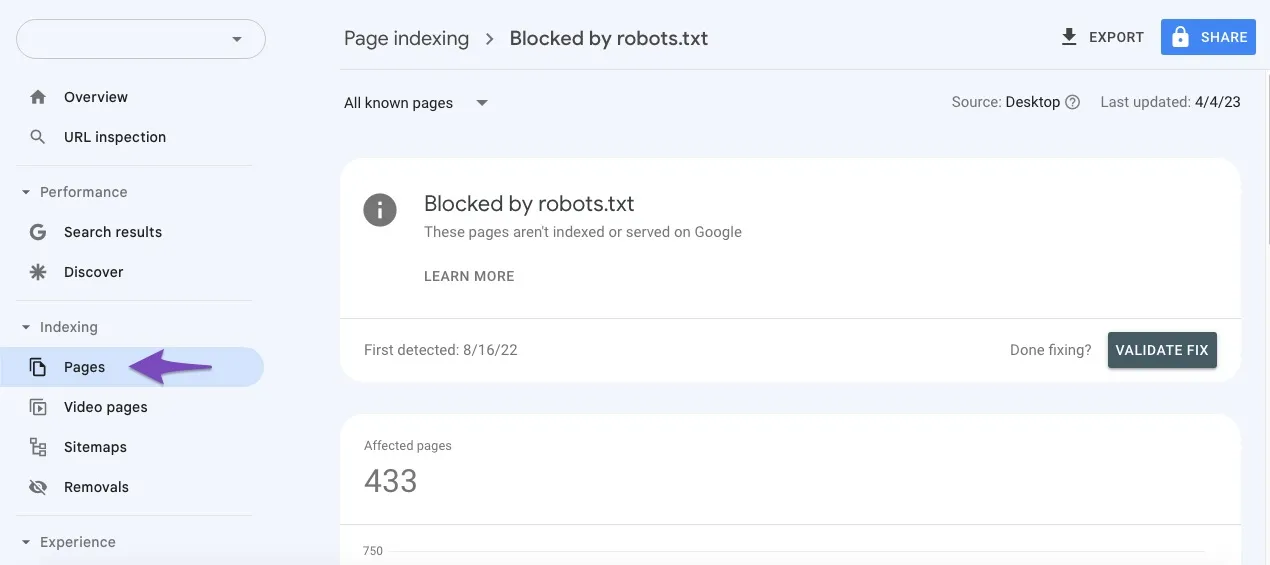
Làm sao để biết trang nào đang bị chặn bởi robots.txt?
Dùng Google Search Console (Indexing > Pages > Why pages aren’t indexed > Blocked by robots.txt). Hoặc crawl toàn bộ site bằng Screaming Frog và lọc theo trạng thái “Blocked by robots.txt”.
Nên chặn trang admin bằng cách nào tốt nhất?
Dùng robots.txt với Disallow: /wp-admin/ kết hợp với meta robots noindex trong header WordPress (có sẵn hoặc thêm bằng plugin). Tuy nhiên, không nên chặn hoàn toàn file CSS/JS của admin vì có thể ảnh hưởng đến báo cáo.
Robots blocked pages có ảnh hưởng đến toàn bộ site không?
Có, nếu chặn quá nhiều trang quan trọng. Nhưng nếu chỉ chặn các trang nội bộ không cần thiết thì không ảnh hưởng tiêu cực đến site chính.
Cập nhật robots.txt bao lâu thì có hiệu lực?
Ngay sau khi file được lưu trên server, bot sẽ đọc lại file robots.txt mỗi khi crawl vào site. Thông thường, Googlebot kiểm tra file này mỗi 24 giờ. Bạn cũng có thể yêu cầu crawl lại thông qua Google Search Console.
Kết Luận
Robots blocked pages là gì? Đó là những trang mà bạn (hoặc lỗi cấu hình) đã yêu cầu công cụ tìm kiếm không truy cập. Hiểu đúng bản chất của cơ chế Disallow, noindex và X-Robots-Tag giúp bạn chủ động kiểm soát luồng crawl, bảo vệ nội dung nhạy cảm và tránh lãng phí ngân sách. Điều quan trọng là phải phân biệt được đâu là chặn có chủ đích (tốt cho SEO) và đâu là lỗi kỹ thuật cần sửa ngay. Hãy thường xuyên kiểm tra Google Search Console, sử dụng các công cụ phân tích SEO và luôn nhớ: chỉ có sự cân bằng giữa việc cho phép crawl nội dung giá trị và chặn các trang rác mới giúp website của bạn phát triển bền vững. Một chiến lược quản lý robots blocked pages tinh tế không chỉ tối ưu hóa ngân sách crawl mà còn tạo nên nền tảng vững chắc cho mọi chiến dịch SEO thành công.
{“@context”:”https://schema.org”,”@type”:”Article”,”headline”:”robots blocked pages là gì”,”articleSection”:”General”,”keywords”:”robots blocked pages là gì”,”datePublished”:”2026-06-30T01:48:39+07:00″,”dateModified”:”2026-06-30T01:48:39+07:00″}
- Khắc phục triệt để lỗi Elementor Nav Menu: Nguyên nhân và giải pháp chi tiết
- Hướng dẫn thiết lập trang chủ WordPress chuyên nghiệp: Từ A đến Z cho người mới bắt đầu
- Hướng Dẫn Toàn Diện Về Popup Trigger Elementor: Từ Cơ Bản Đến Nâng Cao
- Woocommerce Cancel Subscription Lỗi: Nguyên Nhân Và Cách Khắc Phục Toàn Diện
- WordPress Migrate File Lỗi: Nguyên Nhân, Cách Khắc Phục và Hướng Dẫn Toàn Diện
Bài viết cùng chủ đề:
-

Device Breakdown Traffic Là Gì? Bí Quyết Phân Tích Lưu Lượng Theo Thiết Bị Để Tối Ưu SEO
-

Top Countries Traffic Là Gì? Bí Quyết Phân Tích Lưu Lượng Truy Cập Theo Quốc Gia Để Tối Ưu Chiến Lược SEO Toàn Cầu
-

Keyword Ranking Distribution Là Gì? Bí Quyết Phân Bổ Từ Khóa Để Thống Trị Bảng Xếp Hạng
-

Traffic Share Là Gì? Hướng Dẫn Toàn Diện Cách Phân Tích Thị Phần Traffic Để Tối Ưu Chiến Lược SEO
-

Share of Voice trong Ahrefs là gì? Hướng dẫn toàn diện từ A-Z để thống trị thị trường tìm kiếm
-
Traffic Estimation Là Gì? Hướng Dẫn Chi Tiết Cách Dự Báo Lưu Lượng Website Chính Xác
-

SEO Metrics là gì trong Ahrefs? Bí kíp đọc vị mọi chỉ số để làm chủ SEO
-
Domain Authority Comparison Là Gì? Hướng Dẫn Toàn Diện So Sánh Chỉ Số DA Từ A-Z
-

Disavow Suggestions Là Gì? Hướng Dẫn Chi Tiết Để Bảo Vệ Website Khỏi Backlink Xấu
-

Link Detox Là Gì? Hướng Dẫn Toàn Diện Để Lọc Sạch Hồ Sơ Backlink
-

Toxic Links trong Ahrefs Là Gì? Hướng Dẫn Toàn Diện Nhận Diện & Xử Lý Backlink Độc Hại
-

Link Velocity trong Ahrefs là gì? Cách tối ưu tốc độ tăng trưởng backlink để leo hạng nhanh
-
Backlink Growth Là Gì? Chiến Lược Tăng Trưởng Backlink Toàn Diện Cho SEO
-

Orphan Pages Là Gì Trong Ahrefs? Cách Tìm Và Khắc Phục Triệt Để
-
Log File Analysis Ahrefs Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho SEO Chuyên Nghiệp
-

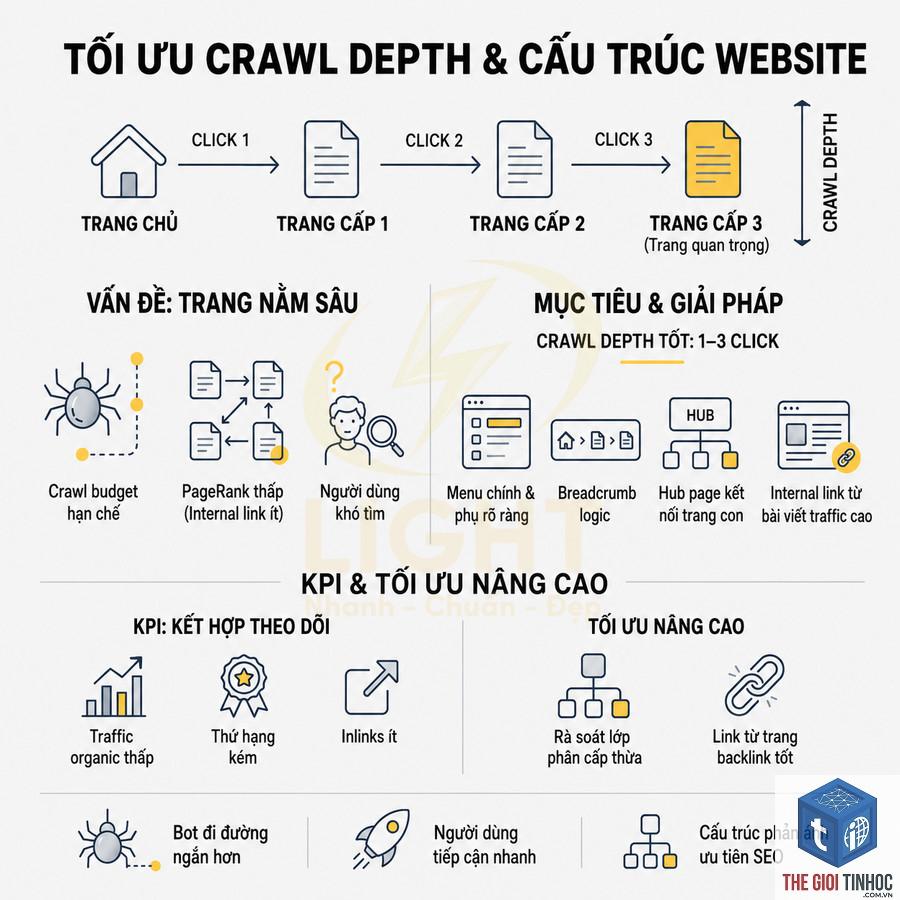
Crawl Depth Trong Ahrefs Là Gì? Hướng Dẫn Toàn Diện Tối Ưu Chiến Lược Crawl Ngân Sách