Named Entity Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Về Nhận Dạng Thực Thực Thể Trong Xử Lý Ngôn Ngữ Tự Nhiên

Th6
Trong thế giới xử lý ngôn ngữ tự nhiên và trí tuệ nhân tạo, named entity là gì luôn là câu hỏi nền tảng mà bất kỳ ai làm việc với dữ liệu văn bản đều cần nắm vững. Nhận dạng thực thể có tên (Named Entity Recognition – NER) là một kỹ thuật trích xuất thông tin quan trọng, có khả năng xác định và phân loại các thực thể cụ thể như tên người, tổ chức, địa điểm, ngày tháng, số tiền và nhiều loại khác từ văn bản phi cấu trúc. Công nghệ này đã trở thành xương sống của nhiều ứng dụng thông minh, từ công cụ tìm kiếm Google, trợ lý ảo Siri, đến hệ thống gợi ý nội dung và phân tích tài chính.
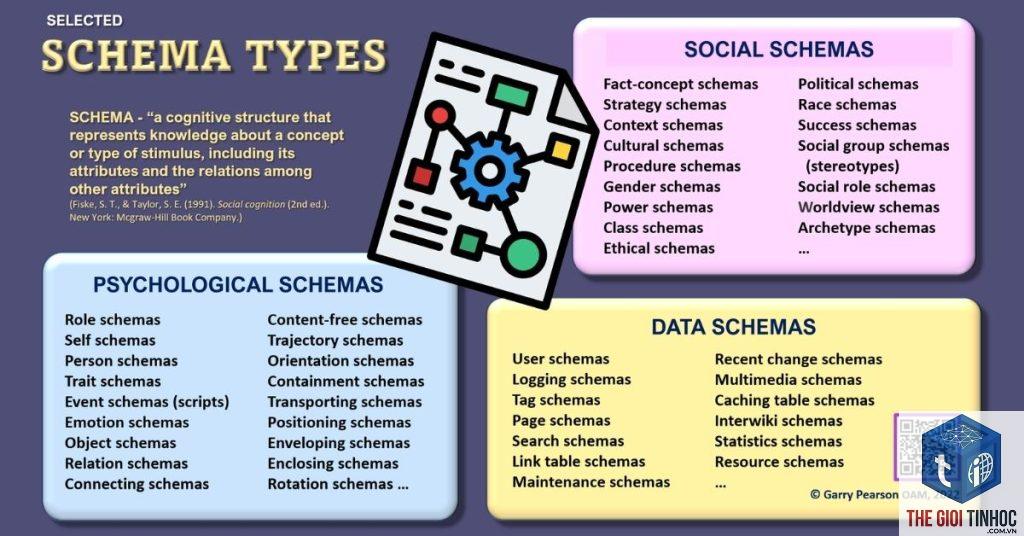
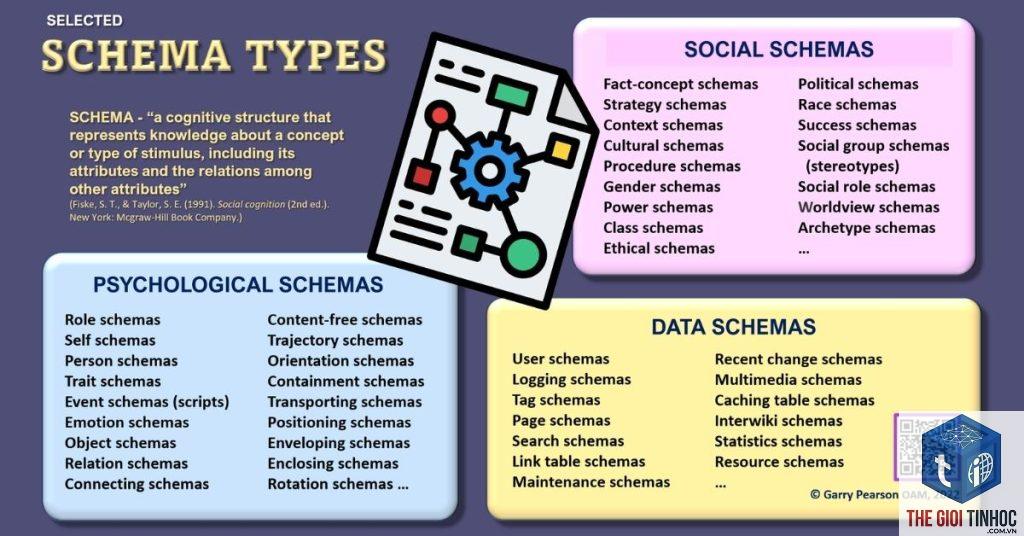
Định Nghĩa Chi Tiết Về Named Entity
Named entity, hay thực thể có tên, là một thuật ngữ trong lĩnh vực xử lý ngôn ngữ tự nhiên dùng để chỉ các đối tượng cụ thể, có thể nhận dạng được trong thế giới thực, thường được biểu thị bằng một cái tên riêng. Một thực thể có tên không chỉ đơn thuần là một từ ngữ thông thường mà mang một ý nghĩa đặc biệt, gắn liền với một thực thể duy nhất, có thể được phân loại vào các nhóm như người, địa danh, tổ chức, sản phẩm, sự kiện, ngày tháng, số liệu, v.v.
Bản chất của việc hiểu named entity là gì nằm ở khả năng phân biệt giữa một từ thông thường và một thực thể có tên. Ví dụ, từ “Apple” trong câu “Tôi ăn một quả apple” là danh từ chung chỉ loại trái cây, nhưng “Apple” trong câu “Apple vừa ra mắt iPhone 15” là một thực thể có tên chỉ công ty công nghệ. Nhờ công nghệ NER, máy tính có thể tự động nhận ra sự khác biệt này và phân loại chính xác.
Các Loại Thực Thực Thể Có Tên Phổ Biến
000 USD, 25%
- PRODUCT: Tên sản phẩm, nhãn hàng, ví dụ: iPhone 14, Toyota Camry
- EVENT: Sự kiện, lễ hội, hội nghị, ví dụ: World Cup 2026, Black Friday
- GPE (Geo-Political Entity): Thực thể địa chính trị như quốc gia, thành phố, tiểu bang
- FAC (Facility): Cơ sở hạ tầng như sân bay, bệnh viện, trường học
Nguyên Lý Hoạt Động Của Nhận Dạng Named Entity
Quá trình nhận dạng named entity là gì trong thực tế được thực hiện thông qua các mô hình học máy tiên tiến. Có ba cách tiếp cận chính mà các hệ thống NER sử dụng, mỗi cách có ưu nhược điểm riêng.
Phương Pháp Dựa Trên Rule-Based (Quy Tắc)
Đây là cách tiếp cận cổ điển nhất, sử dụng các mẫu ngôn ngữ, từ điển chuyên ngành và biểu thức chính quy để xác định thực thể. Ví dụ, một quy tắc có thể là: bất kỳ từ nào bắt đầu bằng chữ cái in hoa và đứng sau “ông” hoặc “bà” đều được coi là tên người. Phương pháp này dễ triển khai nhưng kém linh hoạt với ngôn ngữ phức tạp và khó mở rộng.
Phương Pháp Machine Learning Truyền Thống
Các thuật toán như Conditional Random Fields (CRF), Hidden Markov Models (HMM) hay Support Vector Machines (SVM) được huấn luyện trên các bộ dữ liệu đã được gắn nhãn thủ công. Các mô hình này học từ các đặc trưng như chữ viết hoa, vị trí từ trong câu, loại từ (POS tagging) để dự đoán nhãn thực thể. Phương pháp này cho độ chính xác cao hơn rule-based nhưng vẫn phụ thuộc nhiều vào kỹ thuật trích xuất đặc trưng thủ công.
Phương Pháp Deep Learning Hiện Đại
Ngày nay, các mô hình dựa trên kiến trúc Transformer như BERT, RoBERTa, SpaCy, Stanford NER đã cách mạng hóa lĩnh vực NER. Các mô hình này sử dụng cơ chế attention để hiểu ngữ cảnh sâu hơn và tự động học các đặc trưng phức tạp từ dữ liệu thô. Cụ thể, mô hình BERT có thể đạt F1-score trên 92% trên bộ dữ liệu CoNLL-2003, gần với khả năng của con người.
| Phương pháp | Độ chính xác | Yêu cầu dữ liệu | Khả năng mở rộng |
|---|---|---|---|
| Rule-Based | Trung bình (60-75%) | Thấp | Kém |
| Machine Learning | Khá (80-90%) | Cao (cần feature engineering) | Trung bình |
| Deep Learning | Cao (90-95%) | Rất cao (cần dữ liệu lớn) | Tốt |
Ứng Dụng Thực Tế Của Named Entity Trong Đời Sống

Hiểu rõ named entity là gì đã giúp hàng loạt ngành công nghiệp chuyển đổi số thành công.
Công Cụ Tìm Kiếm Và Gợi Ý Nội Dung
Google sử dụng NER để hiểu rõ hơn truy vấn tìm kiếm. Khi bạn gõ “Elon Musk năm 2024”, hệ thống xác định “Elon Musk” là thực thể PERSON và “2024” là thời gian, từ đó hiển thị kết quả chính xác hơn. Các nền tảng tin tức như BBC, Reuters cũng dùng NER để tự động gắn thẻ bài viết với các thực thể liên quan, giúp đề xuất nội dung tương tự.
Trợ Lý Ảo Và Chatbot Thông Minh
Siri, Google Assistant hay Alexa đều dựa vào nhận dạng thực thể để hiểu câu lệnh. Khi bạn nói “Đặt vé máy bay từ Hà Nội đến TP.HCM vào ngày 20 tháng 6”, hệ thống sẽ trích xuất LOC: Hà Nội, TP.HCM và DATE: 20/06.
Phân Tích Tài Chính Và Pháp Lý
Trong lĩnh vực tài chính, NER giúp trích xuất tên công ty, mã chứng khoán, số tiền giao dịch từ các báo cáo tài chính. Hệ thống pháp lý sử dụng để rà soát hợp đồng, xác định các bên liên quan, ngày tháng hiệu lực, điều khoản thanh toán một cách tự động, tiết kiệm hàng nghìn giờ công.
Chăm Sóc Sức Khỏe Và Nghiên Cứu Y Khoa
Các bệnh viện và viện nghiên cứu sử dụng NER để trích xuất thông tin từ hồ sơ bệnh án: tên bệnh nhân, loại thuốc, chẩn đoán, triệu chứng. Điều này hỗ trợ bác sĩ nhanh chóng tổng hợp dữ liệu và hỗ trợ ra quyết định lâm sàng.
Lợi Ích Và Hạn Chế Của Công Nghệ Nhận Dạng Thực Thực Thể
Mặc dù mang lại nhiều lợi ích vượt trội, nhưng bất kỳ công nghệ nào cũng có những thách thức riêng.
Lợi Ích Chính
- Tự động hóa trích xuất thông tin: Giảm sức lao động thủ công, tăng tốc độ xử lý văn bản lên gấp hàng trăm lần
- Tăng độ chính xác: Với deep learning, NER có thể đạt độ chính xác trên 95%, giảm thiểu sai sót so với con người khi làm việc với khối lượng lớn
- Khả năng mở rộng: Dễ dàng tích hợp vào hệ thống lớn như xử lý hàng triệu email, tài liệu pháp lý cùng lúc
- Hỗ trợ đa ngôn ngữ: Các mô hình hiện đại hỗ trợ hàng trăm ngôn ngữ, trong đó tiếng Việt ngày càng được cải thiện
Hạn Chế Cần Lưu Ý
- Ngữ cảnh mơ hồ: Một từ có thể là thực thể trong ngữ cảnh này nhưng không phải trong ngữ cảnh khác, ví dụ “Washington” có thể là địa danh hoặc họ người
- Chi phí gán nhãn dữ liệu: Cần lượng lớn dữ liệu được gán nhãn thủ công chất lượng cao, cực kỳ tốn kém
- Khó khăn với thực thể mới: Hệ thống khó nhận ra các thực thể mới xuất hiện hoặc ít xuất hiện trong dữ liệu huấn luyện
- Ngôn ngữ biến đổi: Tiếng lóng, viết tắt, lỗi chính tả gây khó khăn cho quá trình nhận dạng
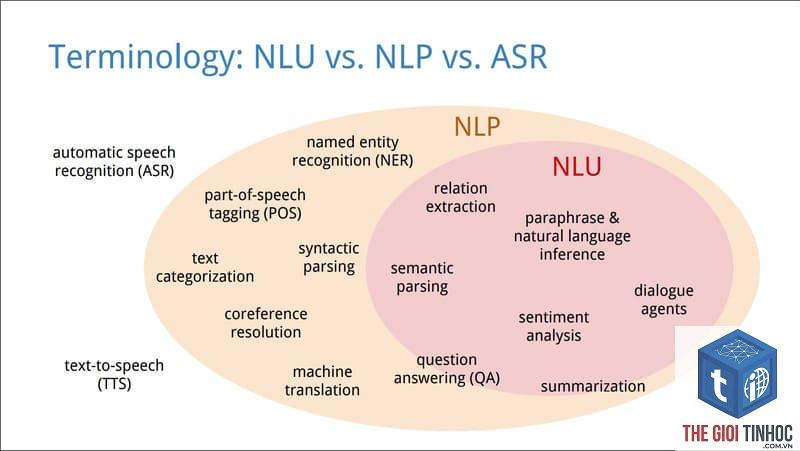
So Sánh Nhận Dạng Named Entity Với Các Kỹ Thuật Xử Lý Ngôn Ngữ Khác
| Kỹ thuật | Mục đích | Ví dụ đầu vào | Kết quả |
|---|---|---|---|
| NER (Named Entity Recognition) | Xác định thực thể có tên | Bill Gates thành lập Microsoft năm 1975 | Bill Gates (PERSON), Microsoft (ORG), 1975 (DATE) |
| POS Tagging | Gán nhãn từ loại | Tôi ăn táo | Tôi (đại từ), ăn (động từ), táo (danh từ) |
| Sentiment Analysis | Phân tích cảm xúc | Sản phẩm này thật tuyệt | Positive (tích cực) |
| Coreference Resolution | Xác định các từ cùng chỉ một đối tượng | Lan đang học. Cô ấy rất chăm | Lan = Cô ấy |
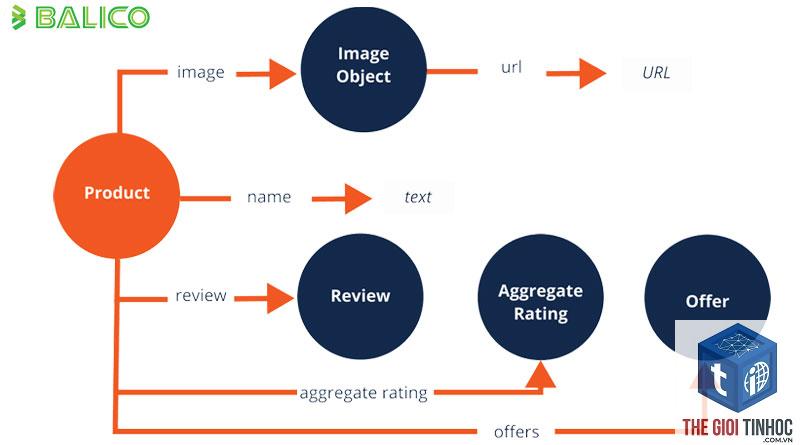
Quy Trình Xây Dựng Hệ Thống Nhận Dạng Named Entity Cơ Bản
Để hiểu rõ hơn named entity là gì trong thực hành, 0
Sai Lầm Thường Gặp Khi Làm Việc Với Named Entity

Cá nhân tôi đã chứng kiến nhiều dự án thất bại vì những sai lầm cơ bản sau đây khi triển khai NER:
- Không xử lý từ viết tắt: Các thực thể như “WHO” (Tổ chức Y tế Thế giới) dễ bị hiểu nhầm thành từ hỏi “who” trong tiếng Anh.
- Bỏ qua ngữ cảnh: Nhãn huấn luyện thiếu sự đồng nhất khiến mô hình học sai. Ví dụ, “Paris” trong “Paris Hilton” là PERSON, nhưng trong “Paris, Pháp” là LOC.
- Lạm dụng mô hình mặc định: Dùng mô hình tiếng Anh cho dữ liệu tiếng Việt mà không tinh chỉnh dẫn đến kết quả tệ.
- Thiếu kiểm định chất lượng: Chỉ dựa vào độ chính xác tổng thể mà không phân tích sai sót theo từng loại thực thể.
- Không cập nhật dữ liệu: Thế giới thay đổi mỗi ngày, các thực thể mới xuất hiện liên tục nên mô hình nhanh chóng lỗi thời.
Lưu Ý Quan Trọng Khi Áp Dụng NER Cho Tiếng Việt
Tiếng Việt có những đặc thù riêng ảnh hưởng mạnh mẽ đến hiệu quả của nhận dạng thực thể. Khi triển khai named entity là gì trong ngữ cảnh tiếng Việt, cần lưu ý:
- Vấn đề tách từ: Tiếng Việt là ngôn ngữ đơn lập, từ có thể là 1 hoặc 2 âm tiết trở lên. Ví dụ “TP.HCM” hay “Thành phố Hồ Chí Minh” cần được xử lý đặc biệt.
- Danh từ riêng không viết hoa đồng nhất: Nhiều người Việt viết tên riêng không viết hoa đúng chuẩn, nhất là trên mạng xã hội.
- Thực thể ghép: Tên người Việt thường 3 từ, tên đường phố dài, dễ gây nhầm lẫn ranh giới thực thể.
- Dữ liệu huấn luyện hạn chế: So với tiếng Anh, dữ liệu NER tiếng Việt chất lượng cao còn ít, đòi hỏi nhiều công sức để gán nhãn.
Câu Hỏi Thường Gặp Về Named Entity

Named entity khác gì với entity trong xử lý ngôn ngữ tự nhiên?
Entity là thuật ngữ rộng hơn, chỉ bất kỳ đối tượng nào có thể xác định (kể cả danh từ chung). Named entity chỉ các thực thể có tên riêng cụ thể, duy nhất. Ví dụ: “người” là entity, “Nguyễn Văn A” là named entity.
Những thư viện NER phổ biến nhất hiện nay là gì?
Các thư viện được dùng rộng rãi bao gồm SpaCy (đơn giản, nhanh, hỗ trợ nhiều ngôn ngữ), Stanford NER (mạnh mẽ, dựa trên CRF), Hugging Face Transformers (cung cấp hàng nghìn mô hình BERT, GPT fine-tuned cho NER), và các API từ Google Cloud, AWS Comprehend.
Làm thế nào để cải thiện độ chính xác của mô hình NER?
Để cải thiện độ chính xác,
Hoàn toàn có thể. Với SpaCy, bạn chỉ cần vài trăm câu dữ liệu gán nhãn để tạo một mô hình NER đơn giản. Các mô hình transformer có sẵn trên Hugging Face có thể được fine-tune với 500-1000 câu để đạt hiệu quả khả quan.
NER có hoạt động tốt với văn bản tiếng Việt không?
Có, nhưng cần tinh chỉnh đúng cách. Các mô hình PhoBERT, ViBERT được huấn luyện riêng cho tiếng Việt, kết hợp với dữ liệu tiếng Việt được gán nhãn sẽ cho kết quả tốt, đạt F1 trên 90% với các thực thể phổ biến.
Kết Luận
Hiểu rõ named entity là gì mở ra cánh cửa cho vô số ứng dụng thông minh trong kỷ nguyên dữ liệu lớn. Nhận dạng thực thể có tên không chỉ là một kỹ thuật xử lý ngôn ngữ, mà còn là nền tảng để máy tính có thể đọc, hiểu và tương tác với ngôn ngữ con người một cách tự nhiên hơn. Với sự phát triển vượt bậc của deep learning, NER ngày càng chính xác và dễ tiếp cận hơn, ngay cả với các doanh nghiệp nhỏ.
Tuy nhiên, thành công không đến từ việc chạy một mô hình mặc định. Nó đòi hỏi sự đầu tư về dữ liệu, hiểu biết về ngôn ngữ mục tiêu, và liên tục cải tiến. Nếu bạn đang có ý định tích hợp NER vào sản phẩm, hãy bắt đầu từ những thực thể đơn giản, đo lường cẩn thận và mở rộng dần. Thế giới dữ liệu phi cấu trúc đang chờ bạn khai phá.
- Xử Lý Lỗi WordPress Database Server Down: Nguyên Nhân & Cách Khắc Phục Từ A-Z
- WordPress Email Queue Stuck: Nguyên Nhân Và Cách Xử Lý Triệt Để
- Knowledge Vault Là Gì? Toàn Tập Về Hệ Thống Lưu Trữ Tri Thức Thông Minh Cho Doanh Nghiệp Hiện Đại
- Theme WordPress vs Template Kit: Sự Khác Biệt Quyết Định Hiệu Suất Website Của Bạn
- Khắc phục lỗi theme wordpress installation failed: Hướng dẫn chi tiết từ A đến Z
Bài viết cùng chủ đề:
-

Cách Sử Dụng Google Search Console Từ A Đến Z: Hướng Dẫn Chi Tiết Cho Website Hiệu Quả
-
Google Search Console là gì? Hướng dẫn toàn diện từ A-Z cho người mới bắt đầu
-

Schema Validator Là Gì? Công Cụ Kiểm Tra Schema Markup Chuẩn SEO Giúp Tăng Lượt Click
-

Schema Generator Là Gì? Công Cụ Tạo Dữ Liệu Cấu Trúc Tối Ưu SEO Website
-

Công Cụ Rich Result Test Hướng Dẫn Chi Tiết Từ A Đến Z Cho Người Làm SEO
-
Schema Validation Là Gì? Toàn Tập Về Xác Thực Cấu Trúc Dữ Liệu Từ Cơ Bản Đến Nâng Cao
-
Speakable Schema là gì? Cách triển khai Schema Markup giúp nội dung được Google Assistant đọc to
-
Howto Schema Là Gì? Bí Quyết Tối Ưu Nội Dung Hướng Dẫn Trong Tìm Kiếm
-

Event Schema Là Gì? Bí Quyết Đánh Bại Đối Thủ Trên Google Với Dữ Liệu Có Cấu Trúc Cho Sự Kiện
-

Service Schema là gì? Hướng dẫn chi tiết từ A đến Z để tối ưu SEO
-

Product Schema Là Gì? Bí Quyết Tối Ưu Hóa Dữ Liệu Sản Phẩm Cho Công Cụ Tìm Kiếm
-

Image Schema Là Gì? Khám Phá Toàn Diện Về Cấu Trúc Nhận Thức Nền Tảng
-

Video Schema Là Gì? Hướng Dẫn Chi Tiết Tối Ưu Video SEO Cho Website
-
WebPage Schema Là Gì? Toàn Tập Hướng Dẫn Chi Tiết Cho Người Làm SEO
-

Website Schema Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho Người Mới Bắt Đầu
-
Person Schema Là Gì? Hướng Dẫn Chi Tiết Cách Triển Khai Schema Markup Cho Con Người