Vector Embedding Là Gì? Giải Mã Công Nghệ Biến Dữ Liệu Thành Ngôn Ngữ Của AI
Th6
Trong thế giới trí tuệ nhân tạo và học máy, một trong những khái niệm nền tảng nhưng cũng dễ gây nhầm lẫn nhất chính là vector embedding. Nếu bạn từng thắc mắc làm thế nào máy tính hiểu được ý nghĩa của từ ngữ, hình ảnh hay âm thanh, câu trả lời nằm ở kỹ thuật này. Vector embedding là một dạng biểu diễn dữ liệu dưới dạng các vector số trong không gian nhiều chiều, cho phép AI nắm bắt mối quan hệ ngữ nghĩa và cấu trúc của dữ liệu gốc. Bài viết này sẽ giải thích chi tiết vector embedding là gì, cách hoạt động, ứng dụng thực tế và những điểm cần lưu ý khi triển khai.
Bản Chất Của Vector Embedding
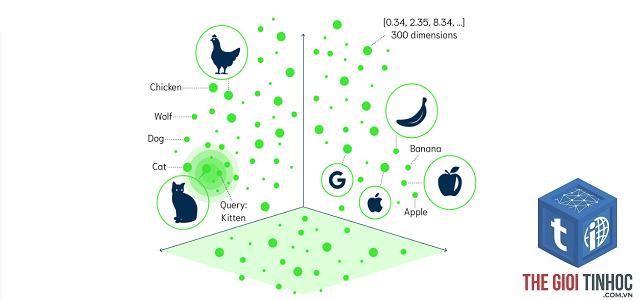
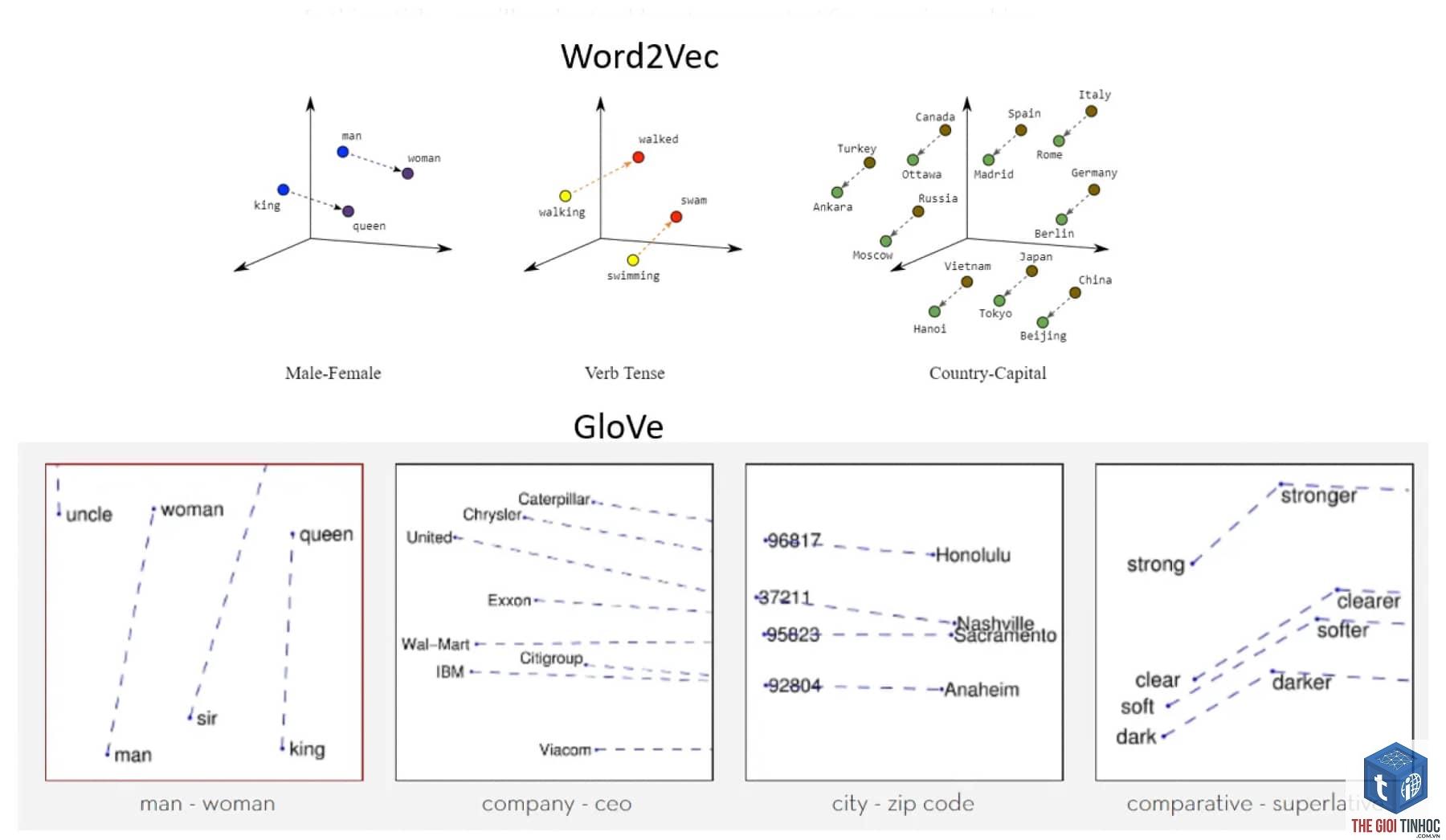
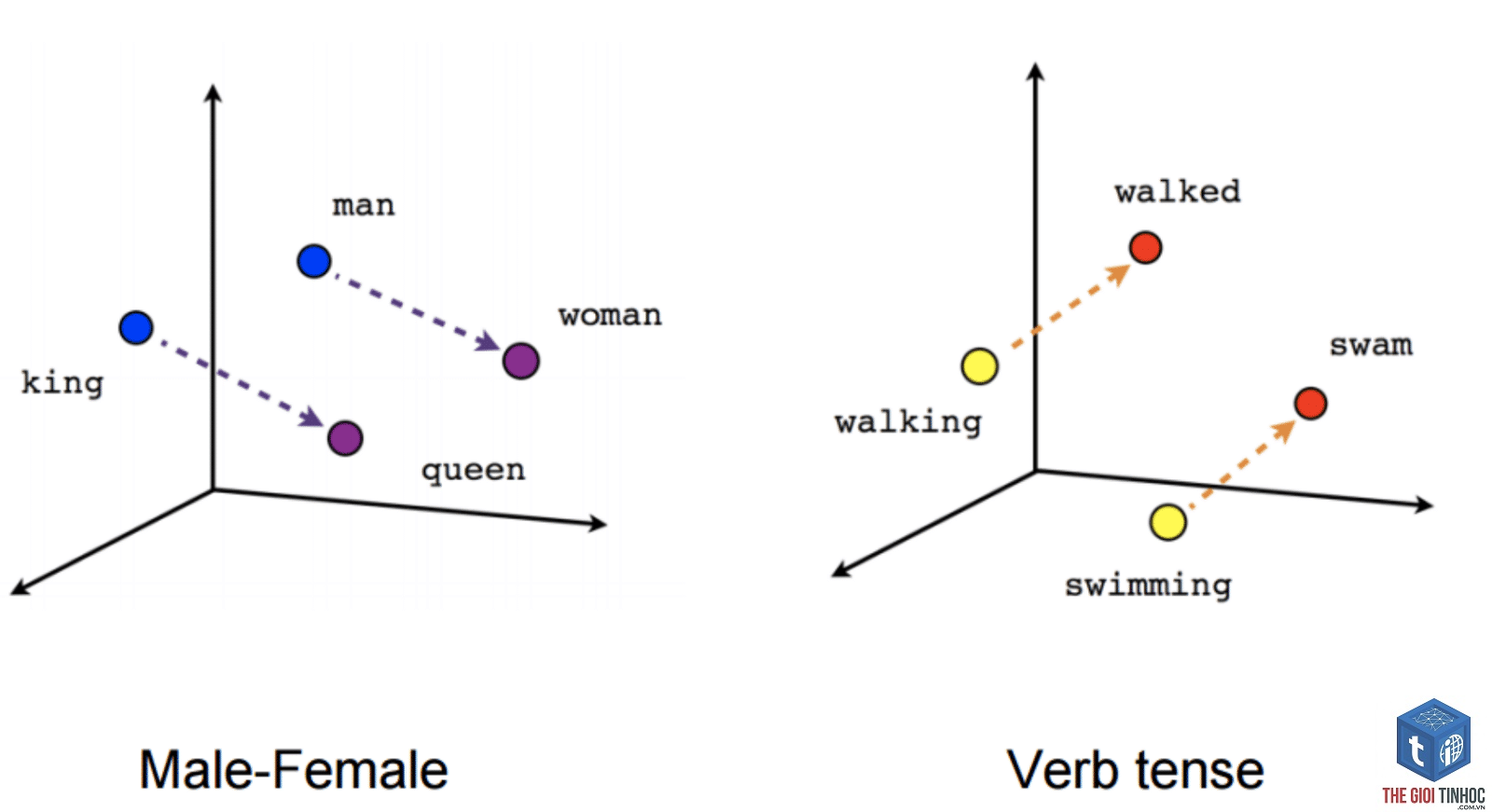
Về mặt toán học, vector embedding là một ánh xạ từ một đối tượng rời rạc (như một từ, một câu hoặc một bức ảnh) sang một vector số thực có kích thước cố định. Mỗi chiều của vector đại diện cho một đặc trưng ẩn nào đó mà mô hình tự học được từ dữ liệu. Ví dụ, trong embedding của từ “vua”, các chiều có thể mã hoá các khái niệm như “quyền lực”, “nam giới”, “hoàng gia”. Nhờ đó, vector embedding giúp máy tính so sánh độ tương đồng ngữ nghĩa giữa các đối tượng: hai từ có nghĩa gần nhau sẽ có các vector gần nhau trong không gian.
Cách Máy Tính “Hiểu” Ngữ Nghĩa Qua Vector
Không giống con người, máy tính chỉ xử lý được số. Để biến dữ liệu phi cấu trúc thành thứ máy tính có thể tính toán, vector embedding đóng vai trò cầu nối. Khi bạn đưa một câu tiếng Việt vào mô hình ngôn ngữ, hệ thống sẽ chuyển mỗi từ thành một vector embedding. Các mô hình như Word2Vec, GloVe hay BERT đều dùng embedding để học ngữ cảnh. Sự khác biệt nằm ở cách embedding được sinh ra: Word2Vec dựa trên ngữ cảnh lân cận, trong khi BERT tạo ra embedding phụ thuộc vào toàn bộ câu (contextual embedding).
| Phương pháp | Đặc điểm | Kích thước vector phổ biến |
|---|---|---|
| Word2Vec (Skip-gram) | Embedding tĩnh, không phụ thuộc ngữ cảnh | 300 |
| GloVe | Embedding tĩnh, dựa trên thống kê đồng xuất hiện | 300 |
| BERT (base) | Embedding động, phụ thuộc ngữ cảnh | 768 |
| OpenAI text-embedding-3-small | Embedding động, hiệu suất cao | 1536 |
Phân Loại Vector Embedding
Tuỳ vào loại dữ liệu đầu vào, vector embedding được chia thành nhiều loại khác nhau. Mỗi loại có kiến trúc riêng và ứng dụng đặc thù.
Word Embedding (Embedding Từ)
Đây là dạng phổ biến nhất. Word embedding chuyển mỗi từ duy nhất trong từ điển thành một vector. Các mô hình như Word2Vec, FastText hay GloVe tạo ra embedding tĩnh – nghĩa là mỗi từ chỉ có một vector duy nhất, bất kể ngữ cảnh. Ưu điểm là nhanh và nhẹ, nhưng hạn chế với từ đa nghĩa. Ví dụ, từ “chân” trong “chân bàn” và “chân trời” sẽ có cùng một embedding, gây mất thông tin ngữ nghĩa.
Sentence Embedding (Embedding Câu)
Để khắc phục hạn chế trên, sentence embedding kết hợp toàn bộ thông tin trong câu để tạo vector đại diện. Các mô hình như Sentence-BERT, Universal Sentence Encoder hay các embedding từ API OpenAI cho phép so sánh ngữ nghĩa giữa các câu hoặc đoạn văn. Kích thước thường từ 512 đến 1536 chiều. Sentence embedding ứng dụng mạnh trong tìm kiếm ngữ nghĩa, phân cụm văn bản và hệ thống hỏi đáp.
Image Embedding (Embedding Ảnh)
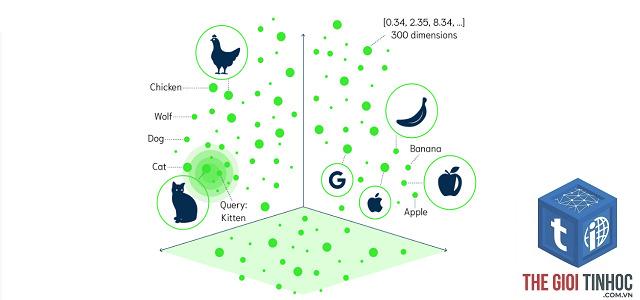
Không chỉ văn bản, hình ảnh cũng được biểu diễn dưới dạng vector nhờ các mạng CNN hoặc Vision Transformer. Mỗi bức ảnh được mã hoá thành vector đặc trưng, cho phép tìm kiếm ảnh tương tự, phân loại và sinh ảnh. Ví dụ trong Google Images, khi bạn tìm “mèo”, hệ thống so sánh vector embedding của ảnh bạn tải lên với hàng triệu vector trong cơ sở dữ liệu.
Quy Trình Tạo Vector Embedding
Việc tạo ra một vector embedding chất lượng đòi hỏi dữ liệu lớn và mô hình học sâu.
- Chọn kiến trúc mô hình: Word2Vec cho embedding từ đơn giản, BERT cho embedding động, hoặc sử dụng API pre-trained.
- Huấn luyện hoặc fine-tune: Mô hình học cách dự đoán từ ngữ cảnh hoặc tối ưu hoá loss function (ví dụ: contrastive loss).
- Trích xuất vector: Lấy đầu ra từ lớp embedding hoặc vector pooler của mô hình.
- Chuẩn hoá: Thường chuẩn hoá L2 để các vector có độ dài bằng nhau, giúp tính similarity chính xác.
- Nắm bắt ngữ nghĩa và mối quan hệ ngầm định giữa các đối tượng (ví dụ: “Paris” gần với “Pháp”).
- Giảm chiều dữ liệu so với biểu diễn one-hot (từ điển 50.000 từ -> vector 300 chiều).
- Cho phép tính toán số học ngữ nghĩa: vector của “vua” – “đàn ông” + “phụ nữ” ≈ “nữ hoàng”.
- Là nền tảng cho nhiều ứng dụng AI như tìm kiếm vector, hệ thống gợi ý, RAG (Retrieval-Augmented Generation).
- Yêu cầu tài nguyên tính toán lớn khi huấn luyện từ đầu.
- Khó giải thích trực quan: mỗi chiều không có ý nghĩa rõ ràng với con người.
- Nhạy cảm với nhiễu: nếu dữ liệu đầu vào có lỗi, embedding có thể bị lệch.
- Không xử lý tốt các từ hiếm hoặc từ mới (out-of-vocabulary) trừ khi dùng kỹ thuật subword như FastText.
- Chọn sai loại embedding: dùng word embedding tĩnh cho bài toán cần hiểu ngữ cảnh (ví dụ: phân tích đa nghĩa) dẫn đến kết quả kém.
- Không chuẩn hoá vector: khi tính cosine similarity, nếu không chuẩn hoá L2, độ đo bị ảnh hưởng bởi độ dài vector.
- Bỏ qua việc kiểm tra độ tương đồng trực quan: nhiều khi embedding sinh ra không phản ánh đúng quan hệ ngữ nghĩa mong muốn.
- Dùng embedding từ mô hình nước ngoài cho dữ liệu tiếng Việt mà không fine-tune: embedding đa ngữ như mBERT có thể hoạt động nhưng hiệu suất chưa tối ưu.
- Không cập nhật embedding khi dữ liệu thay đổi: mô hình static embedding không bắt kịp từ mới hoặc biến thể ngôn ngữ.
Các thư viện phổ biến như Hugging Face Transformers, Gensim hay TensorFlow Hub cung cấp sẵn các mô hình embedding để sử dụng ngay mà không cần huấn luyện lại.
Lợi Ích Và Hạn Chế Của Vector Embedding
Lợi ích
Hạn chế
So Sánh Vector Embedding Với Các Phương Pháp Biểu Diễn Khác
| Kỹ thuật | Biểu diễn | Kích thước | Ngữ nghĩa | Ví dụ |
|---|---|---|---|---|
| One-hot | Vector nhị phân, 1 ở vị trí từ | Kích thước từ điển (rất lớn) | Không có | [0,0,1,0,…] |
| Bag-of-Words | Vector đếm tần suất | Kích thước từ điển | Rất ít | [2,0,1,…] |
| TF-IDF | Vector trọng số tần suất * nghịch đảo tài liệu | Kích thước từ điển | Một phần | [0.3, 0, 1.2,…] |
| Vector Embedding | Vector số thực dày đặc | Thường 100-1536 chiều | Cao (ngữ nghĩa và cú pháp) | [0.23, -0.89, 0.41,…] |
So với one-hot (thưa và không ngữ nghĩa), vector embedding dày đặc và giàu thông tin hơn. TF-IDF có phần ngữ nghĩa dựa trên tài liệu nhưng vẫn thưa và không linh hoạt. Embedding là lựa chọn tối ưu cho hầu hết bài toán NLP hiện đại.
Ứng Dụng Thực Tế Của Vector Embedding
Tìm Kiếm Ngữ Nghĩa (Semantic Search)
Thay vì tìm kiếm dựa trên từ khoá chính xác, hệ thống tìm kiếm vector so sánh độ tương đồng cosine giữa embedding của truy vấn và tài liệu. Google, Wikipedia hay các nền tảng thương mại điện tử đều sử dụng kỹ thuật này để hiểu đúng ý định người dùng. Ví dụ: tìm “cách sửa lỗi Macbook chậm” thay vì “Macbook chậm fix” – kết quả vẫn chính xác.
Hệ Thống Gợi Ý (Recommendation)
Netflix, Spotify, Shopee dùng vector embedding của người dùng và sản phẩm. Mỗi user và item được biểu diễn bởi một vector. Khoảng cách giữa vector user và vector item quyết định xác suất người dùng thích item đó. Mô hình ma trận phân rã (Matrix Factorization) thực chất đang học các embedding tiềm ẩn.
RAG (Retrieval-Augmented Generation)
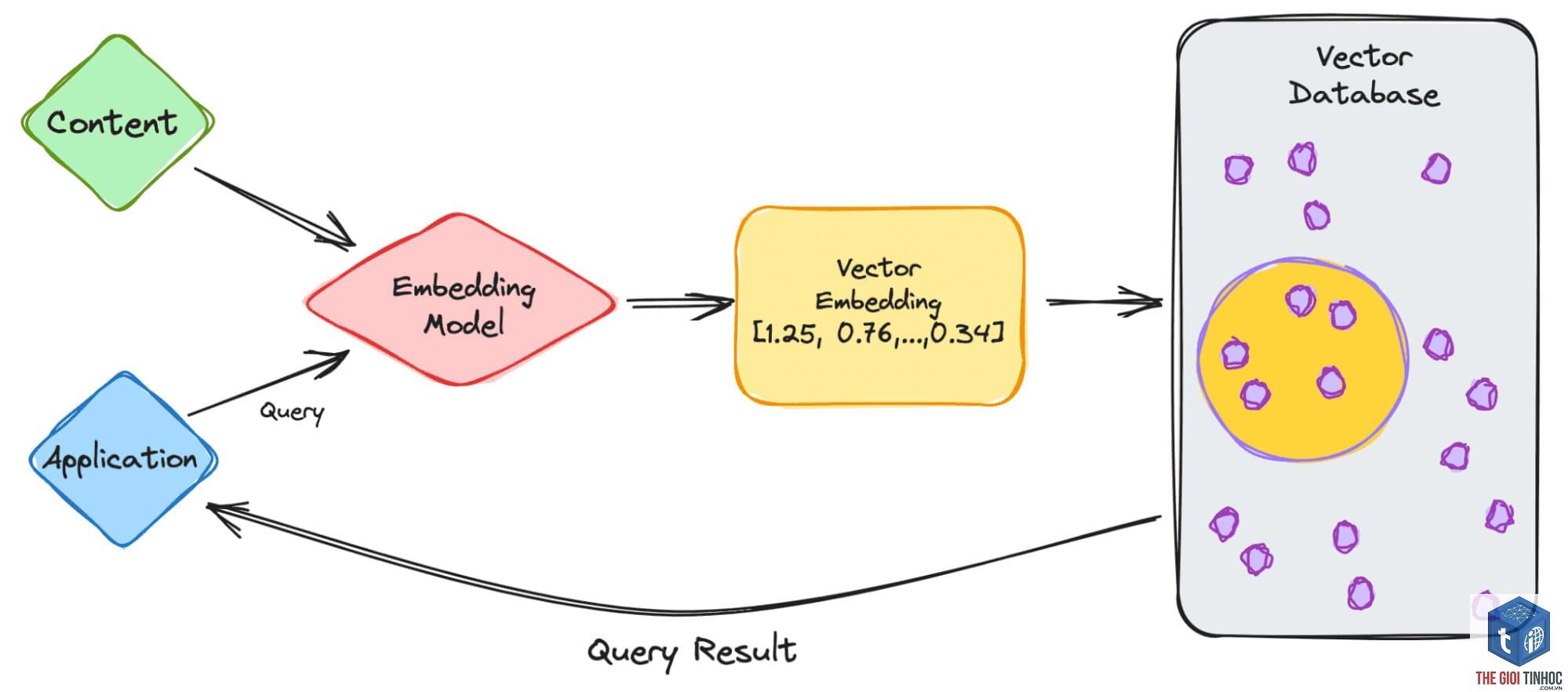
Đây là ứng dụng nổi bật của LLM (Large Language Model). Khi bạn hỏi chatbot về thông tin nội bộ công ty, hệ thống RAG trước tiên chuyển câu hỏi thành vector embedding. Sau đó truy xuất các đoạn tài liệu phù hợp từ database vector (ví dụ: Pinecone, Weaviate, Qdrant). Cuối cùng, LLM sinh câu trả lời dựa trên các đoạn đó. Điều này giúp chatbot chính xác, cập nhật và giảm ảo giác.
Phân Cụm Và Phân Loại Văn Bản
Dùng K-means hoặc DBSCAN trên embedding để nhóm các văn bản có chủ đề tương tự. Phân loại spam, phân tích cảm xúc, gán nhãn chủ đề đều có thể tận dụng đầu ra từ embedding.
Sai Lầm Thường Gặp Khi Làm Việc Với Vector Embedding
Lưu Ý Quan Trọng Khi Triển Khai Vector Embedding
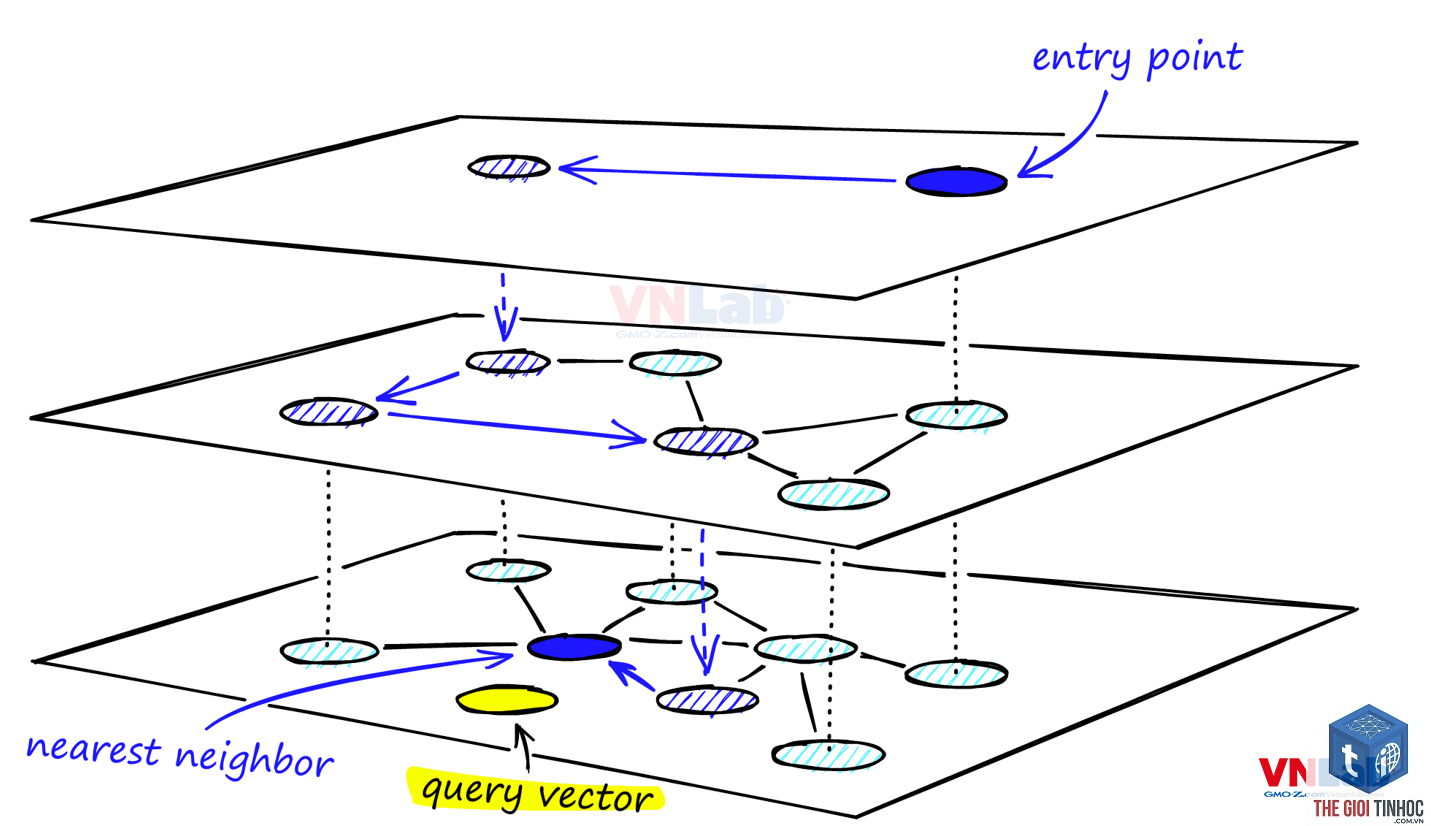
Đảm bảo chiều dài vector phù hợp với tài nguyên và yêu cầu độ chính xác. Kích thước 384 hoặc 768 có thể đủ cho nhiều tác vụ, nhưng nếu cần độ chính xác cao hơn, hãy cân nhắc embedding 1536 chiều. Đối với dữ liệu tiếng Việt, ưu tiên các mô hình pre-trained trên ngữ liệu lớn hoặc fine-tune trên tập dữ liệu đặc thù. Khi lưu trữ hàng triệu vector, cần sử dụng cơ sở dữ liệu vector chuyên dụng (vector database) như FAISS, Pinecone, Milvus để tối ưu tốc độ truy vấn. Ngoài ra, cần kiểm tra bias trong embedding – các mô hình huấn luyện trên dữ liệu có thể học phải định kiến xã hội, ảnh hưởng đến quyết định AI.
Câu Hỏi Thường Gặp Về Vector Embedding
Vector embedding khác với one-hot encoding như thế nào?
One-hot tạo vector nhị phân với độ dài bằng từ điển, phần lớn là số 0 (thưa). Vector embedding là vector dày đặc, kích thước nhỏ hơn nhiều và chứa thông tin ngữ nghĩa. Với từ điển 50.000 từ, one-hot cần vector 50.000 chiều, trong khi embedding chỉ cần 300-1000 chiều.
Làm thế nào để tạo vector embedding cho riêng dữ liệu của mình?
Có thể dùng mô hình pre-trained từ Hugging Face (như sentence-transformers/all-MiniLM-L6-v2) để sinh embedding cho văn bản. Nếu muốn tuỳ chỉnh,
Có. Image embedding biểu diễn ảnh thành vector, dùng trong reverse image search (tìm ảnh bằng ảnh), phân loại ảnh, phát hiện vật thể. Các mô hình như CLIP của OpenAI cho phép kết hợp embedding văn bản và ảnh trong cùng không gian.
Chi phí lưu trữ và truy vấn vector embedding có cao không?
Mỗi vector embedding thường chiếm vài trăm byte đến vài KB. Với 10 triệu vector kích thước 768 chiều (4 byte float) ~ 30GB. Truy vấn gần đúng (ANN – Approximate Nearest Neighbor) có thể đạt độ trễ vài mili giây. Các dịch vụ cloud vector database tính phí theo dung lượng và số lượng truy vấn, nhưng vẫn hợp lý với doanh nghiệp vừa và nhỏ.
Tại sao embedding cần được chuẩn hoá?
Khi tính độ tương đồng cosine (cosine similarity), chuẩn hoá L2 đưa tất cả vector về cùng độ dài 1, giúp kết quả chỉ phụ thuộc vào góc giữa vector mà không bị ảnh hưởng bởi độ dài. Điều này đảm bảo so sánh công bằng giữa các vector.
Kết Luận
Vector embedding là nền tảng không thể thiếu trong hầu hết các hệ thống AI hiện đại, từ xử lý ngôn ngữ tự nhiên, thị giác máy tính cho đến các ứng dụng tìm kiếm và gợi ý. Hiểu rõ vector embedding là gì, cách nó mã hoá ngữ nghĩa và cách triển khai đúng sẽ giúp bạn khai thác tối đa sức mạnh của dữ liệu phi cấu trúc. Dù bạn là nhà phát triển, nhà khoa học dữ liệu hay người mới bắt đầu, nắm vững khái niệm này là bước đệm quan trọng để xây dựng các ứng dụng thông minh, chính xác và hiệu quả. Trong tương lai, khi embedding ngày càng tinh vi hơn (ví dụ: multimodal embedding kết hợp văn bản, ảnh và âm thanh), khả năng của AI sẽ tiếp tục vươn xa, mở ra những giải pháp đột phá cho mọi ngành công nghiệp.
- Hướng dẫn chi tiết cách tạo category con WordPress từ A-Z cho người mới bắt đầu
- Không cập nhật được theme WordPress: Nguyên nhân và cách khắc phục triệt để
- Theme WordPress Typography Lỗi: Nguyên Nhân, Cách Khắc Phục và Tối Ưu Font Chữ
- Cách khắc phục lỗi Plugin WordPress Ownership Error triệt để và an toàn nhất
- Hướng dẫn chi tiết WordPress Server Debug: Từ khái niệm đến triển khai thực tế
Bài viết cùng chủ đề:
-

Schema Validator Là Gì? Công Cụ Kiểm Tra Schema Markup Chuẩn SEO Giúp Tăng Lượt Click
-

Schema Generator Là Gì? Công Cụ Tạo Dữ Liệu Cấu Trúc Tối Ưu SEO Website
-

Công Cụ Rich Result Test Hướng Dẫn Chi Tiết Từ A Đến Z Cho Người Làm SEO
-
Schema Validation Là Gì? Toàn Tập Về Xác Thực Cấu Trúc Dữ Liệu Từ Cơ Bản Đến Nâng Cao
-
Speakable Schema là gì? Cách triển khai Schema Markup giúp nội dung được Google Assistant đọc to
-
Howto Schema Là Gì? Bí Quyết Tối Ưu Nội Dung Hướng Dẫn Trong Tìm Kiếm
-

Event Schema Là Gì? Bí Quyết Đánh Bại Đối Thủ Trên Google Với Dữ Liệu Có Cấu Trúc Cho Sự Kiện
-

Service Schema là gì? Hướng dẫn chi tiết từ A đến Z để tối ưu SEO
-

Product Schema Là Gì? Bí Quyết Tối Ưu Hóa Dữ Liệu Sản Phẩm Cho Công Cụ Tìm Kiếm
-

Image Schema Là Gì? Khám Phá Toàn Diện Về Cấu Trúc Nhận Thức Nền Tảng
-

Video Schema Là Gì? Hướng Dẫn Chi Tiết Tối Ưu Video SEO Cho Website
-
WebPage Schema Là Gì? Toàn Tập Hướng Dẫn Chi Tiết Cho Người Làm SEO
-

Website Schema Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho Người Mới Bắt Đầu
-
Person Schema Là Gì? Hướng Dẫn Chi Tiết Cách Triển Khai Schema Markup Cho Con Người
-
Organization Schema Là Gì? Hướng Dẫn Chi Tiết Triển Khai Structured Data Cho Doanh Nghiệp
-

NewsArticle Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Website Tin Tức