Crawl Budget Là Gì? Toàn Tập Kiến Thức Chuyên Sâu Về Ngân Sách Thu Thập Dữ Liệu Cho SEO

Th6
Crawl budget là một trong những khái niệm cốt lõi mà bất kỳ SEO chuyên nghiệp nào cũng phải nắm vững. Nó quyết định tần suất và số lượng trang web của bạn được Googlebot thu thập mỗi ngày. Hiểu rõ crawl budget là gì và cách tối ưu hóa nó giúp website của bạn được index nhanh hơn, tiết kiệm tài nguyên máy chủ và cải thiện thứ hạng tổng thể. Bài viết này sẽ đưa bạn từ những khái niệm cơ bản nhất đến các chiến lược nâng cao để quản lý hiệu quả ngân sách thu thập dữ liệu.
Định Nghĩa Chính Xác Về Crawl Budget

Crawl budget, hay còn gọi là ngân sách thu thập dữ liệu, là số lượng URL mà Googlebot (công cụ thu thập thông tin của Google) có thể và sẽ thu thập trên website của bạn trong một khung thời gian nhất định, thường là một ngày. Nó không phải là một con số cố định mà thay đổi linh hoạt dựa trên nhiều yếu tố như kích thước website, tốc độ tải trang, tình trạng sức khỏe của máy chủ và mức độ quan trọng của nội dung.
Google phân bổ crawl budget dựa trên hai yếu tố chính: crawl demand (nhu cầu thu thập) và crawl capacity (năng lực thu thập). Crawl demand phản ánh mức độ phổ biến và sự thay đổi thường xuyên của nội dung trên trang. Crawl capacity là giới hạn kỹ thuật mà máy chủ của
Đối với các website nhỏ (dưới 500 trang), crawl budget thường không phải là vấn đề lớn vì Googlebot có thể thu thập toàn bộ site trong vài giờ. Nhưng với các trang web lớn (thương mại điện tử, tin tức, diễn đàn), việc tối ưu crawl budget trở thành yếu tố sống còn. Nếu không quản lý tốt, Googlebot có thể bỏ qua các trang quan trọng, tập trung vào nội dung vô giá trị, dẫn đến giảm khả năng index và ảnh hưởng tiêu cực đến thứ hạng.
Tối ưu crawl budget giúp bạn đảm bảo rằng các trang chiến lược (sản phẩm bán chạy, bài viết mới, landing page) luôn được thu thập kịp thời. Điều này đặc biệt quan trọng trong các chiến dịch Marketing ngắn hạn hoặc khi ra mắt sản phẩm mới.
Cách Kiểm Tra Crawl Budget Trên Website Của Bạn
Sử Dụng Google Search Console
Vào mục Crawl Stats (Thống kê thu thập dữ liệu) trong Google Search Console. Tại đây, bạn sẽ thấy biểu đồ về số lượng yêu cầu crawl mỗi ngày, tổng dung lượng tải xuống và thời gian phản hồi trung bình. Dữ liệu này cho thấy Googlebot đang hoạt động thế nào trên website của bạn.
Phân Tích File Log Server
Đây là phương pháp chính xác nhất. File log ghi lại tất cả các yêu cầu từ Googlebot, bao gồm URL được truy cập, thời gian, mã trạng thái HTTP. Phân tích log cho biết chính xác trang nào được crawl nhiều nhất, trang nào bị bỏ qua, và phát hiện các vấn đề như crawl loops hoặc lỗi 404.
Công Cụ Bên Thứ Ba
Các công cụ như Screaming Frog, Botify, hoặc DeepCrawl có tính năng mô phỏng và phân tích crawl budget. Chúng giúp bạn phát hiện các URL không cần thiết, nội dung trùng lặp, và đưa ra khuyến nghị tối ưu hóa.
Hướng Dẫn Tối Ưu Crawl Budget Hiệu Quả
Tối Ưu Hóa Cấu Trúc Liên Kết Nội Bộ
Liên kết nội bộ là công cụ mạnh mẽ để dẫn dắt Googlebot. Hãy đảm bảo mọi trang quan trọng đều được liên kết từ ít nhất một trang khác trong site. Sử dụng breadcrumb, footer links, và các widget bài viết liên quan. Tránh tạo ra các “orphan pages” – trang không có liên kết nội bộ đến.
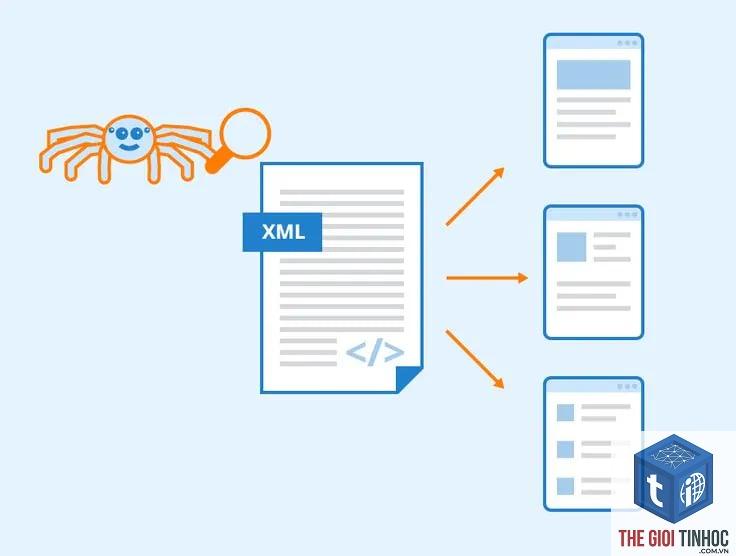
Kiểm Soát Sitemap XML Và Robots.txt
Sitemap XML nên chỉ bao gồm các URL có giá trị index, không chứa trang lỗi, trang tạm thời, hoặc nội dung trùng lặp. Cập nhật sitemap mỗi khi có nội dung mới và gửi lại cho Google qua Search Console. Trong robots.txt, sử dụng lệnh Disallow để chặn các khu vực không cần thiết (như trang admin, trang kết quả tìm kiếm nội bộ, các tham số URL vô ích).
Nâng Cao Tốc Độ Và Hiệu Suất Máy Chủ
Tối ưu hóa thời gian phản hồi server (TTFB) xuống dưới 200ms. Sử dụng CDN, nén file, tối ưu hình ảnh, và giảm thiểu các request không cần thiết. Một máy chủ khỏe mạnh sẽ cho phép Googlebot thu thập nhiều URL hơn trong cùng một khoảng thời gian.
Giảm Thiểu Nội Dung Trùng Lặp
Nội dung trùng lặp là kẻ thù của crawl budget. Sử dụng thẻ canonical đúng cách, chuyển hướng 301 cho các trang trùng, và tránh tạo ra nhiều phiên bản URL khác nhau cho cùng một nội dung (ví dụ: example.com/page và example.com/page?ref=123).
Quản Lý Trang Lỗi Và Redirect Chain
Trang 404, 410 và các chuỗi redirect (301 dài dòng) đều tiêu tốn crawl budget. Hãy thường xuyên kiểm tra và sửa lỗi 404, đảm bảo các redirect chỉ có một bước duy nhất. Các trang lỗi nên trả về mã trạng thái thích hợp thay vì redirect về trang chủ.
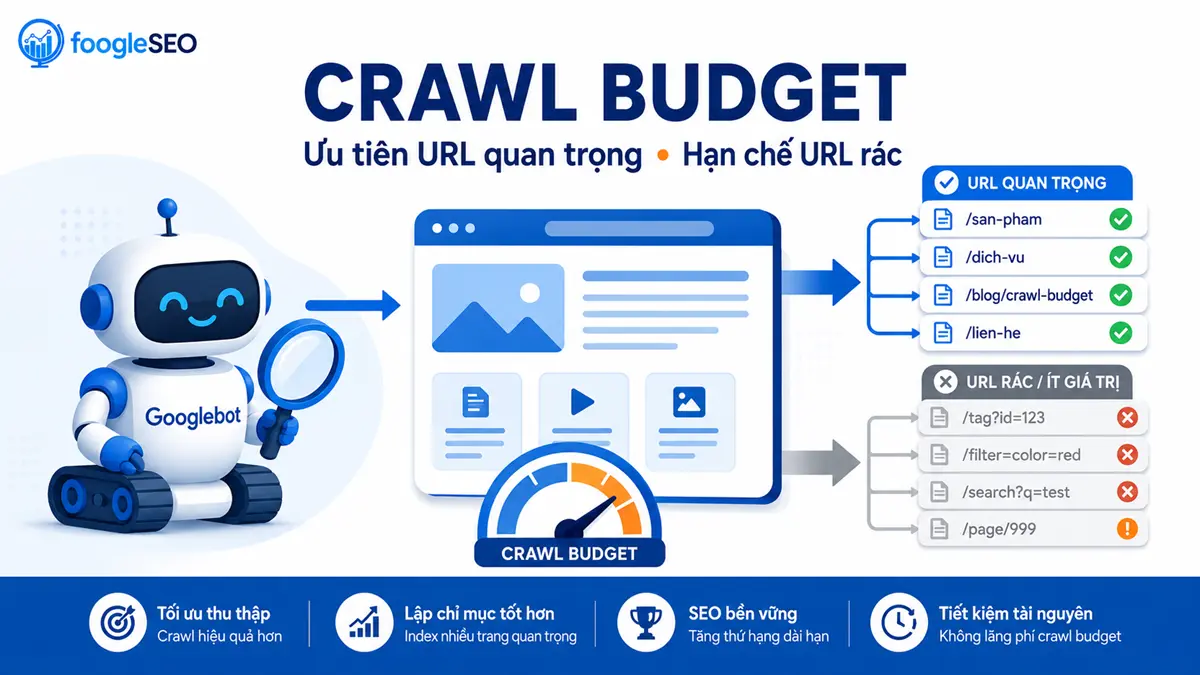
So Sánh Crawl Budget Giữa Các Loại Website

| Loại website | Đặc điểm crawl budget | Thách thức chính |
|---|---|---|
| Thương mại điện tử (e-commerce) | Crawl budget lớn do số lượng sản phẩm nhiều, thường xuyên thay đổi | Nội dung trùng lặp (biến thể sản phẩm), tham số URL, trang lọc sản phẩm |
| Tin tức / Blog | Crawl demand cao, ưu tiên bài mới | Cần cân bằng giữa bài mới và bài cũ, tránh lãng phí vào nội dung cũ không còn giá trị |
| Diễn đàn / Cộng đồng | Crawl budget phân tán do nhiều chủ đề, bình luận | Phải chặn các trang người dùng, trang tìm kiếm nội bộ, nội dung spam |
| Trang doanh nghiệp nhỏ | Crawl budget thường dư thừa | Ít vấn đề, chủ yếu cần đảm bảo cấu trúc đơn giản |
Sai Lầm Thường Gặp Khi Quản Lý Crawl Budget
1. Chặn Googlebot quá mức trong robots.txt
Nhiều người chặn toàn bộ thư mục CSS, JS để tiết kiệm băng thông nhưng vô tình làm Googlebot không thể render trang, ảnh hưởng đến crawl budget âm tính.
2. Quá lạm dụng thẻ noindex
Dùng noindex cho quá nhiều trang có thể khiến Googlebot bối rối và giảm nhu cầu thu thập tổng thể.
3. Không theo dõi log server thường xuyên
Nhiều SEO chỉ dựa vào Search Console mà bỏ qua log server, dẫn đến bỏ sót các vấn đề crawl sâu.
4. Bỏ qua các trang có dung lượng lớn
File PDF, video, hình ảnh không tối ưu có thể làm chậm quá trình crawl, giảm hiệu suất tổng thể.
Cách Tránh Những Sai Lầm Này
- Chỉ chặn các tài nguyên không cần thiết cho việc hiển thị nội dung.
- Sử dụng noindex một cách có chọn lọc, kết hợp với canonical.
- Thiết lập quy trình phân tích log hàng tuần hoặc hàng tháng.
- Tối ưu hóa kích thước file, nén PDF, và sử dụng lazy load cho hình ảnh.
Mối Liên Hệ Giữa Crawl Budget Và Core Web Vitals
Google đã xác nhận rằng Core Web Vitals là một tín hiệu xếp hạng. Nhưng ít ai biết rằng chúng cũng tác động đến crawl budget. Một website có LCP dưới 2.5 giây, FID dưới 100ms và CLS dưới 0.1 sẽ được Googlebot đánh giá cao và có khả năng nhận được crawl budget tốt hơn. Ngược lại, các website có Core Web Vitals kém có thể bị giảm tốc độ crawl, đặc biệt là trên thiết bị di động.
Vì vậy, đầu tư vào tốc độ trang không chỉ cải thiện trải nghiệm người dùng mà còn tối ưu hóa crawl budget một cách gián tiếp.
Crawl Budget Và Googlebot’s Crawl Rate Limiting
Googlebot có cơ chế tự động giới hạn tốc độ thu thập (crawl rate limiting). Khi máy chủ bắt đầu chậm lại hoặc trả về lỗi, Googlebot sẽ giảm số lượng yêu cầu và tăng khoảng thời gian giữa các lần crawl. Nếu tình trạng kéo dài, giới hạn này có thể trở nên vĩnh viễn cho đến khi website được cải thiện. cat=123&sort=price là nỗi ác mộng cho crawl budget. Hãy sử dụng rewrite rules để tạo URL tĩnh, thân thiện. Bên cạnh đó, tránh tạo nhiều URL khác nhau trỏ đến cùng một nội dung (ví dụ: có hoặc không có dấu gạch chéo cuối).
Vai Trò Của Internal Link Trong Việc Điều Hướng Crawl Budget

Internal link là cách trực tiếp nhất để thông báo cho Googlebot biết trang nào quan trọng. Một trang được liên kết từ nhiều trang khác (có PageRank nội bộ cao) sẽ được ưu tiên crawl. Ngược lại, các trang ít liên kết hoặc không có liên kết sẽ bị bỏ qua. Hãy xây dựng hệ thống internal link theo kiểu silo hoặc hub-and-spoke để truyền sức mạnh đến các trang mục tiêu.
Câu Hỏi Thường Gặp Về Crawl Budget
Crawl budget có giống với số lần Googlebot ghé thăm website mỗi ngày?
Không hoàn toàn. Crawl budget là tổng số URL được crawl, không phải số lần Googlebot truy cập. Mỗi lần Googlebot đến, nó có thể crawl nhiều URL cùng lúc.
Làm thế nào để biết website của tôi cần tối ưu crawl budget?
Nếu website của bạn có hơn 10.000 URL và bạn nhận thấy các trang mới không được index kịp thời, hoặc tỷ lệ index thấp (dưới 50%), đó là dấu hiệu cần tối ưu.
Có nên tăng tốc độ crawl bằng cách yêu cầu trong Search Console?
Không trực tiếp. Tối ưu crawl budget giúp các trang quan trọng được index nhanh hơn, từ đó có cơ hội xếp hạng sớm hơn. Hiệu quả thường thấy sau vài tuần đến vài tháng.
Google có công bố con số crawl budget cụ thể không?
Không. Google không đưa ra con số chính xác vì nó phụ thuộc vào nhiều yếu tố động. Bạn chỉ có thể ước lượng thông qua dữ liệu Search Console và log server.
Kết Luận
Crawl budget là một khái niệm kỹ thuật nhưng có tính ứng dụng rất cao trong SEO thực tế. Việc hiểu rõ crawl budget là gì và áp dụng các chiến lược tối ưu sẽ giúp website của bạn vận hành hiệu quả hơn dưới góc nhìn của Googlebot. Bắt đầu từ việc kiểm tra crawl stats, phân tích log server, tối ưu cấu trúc internal link và giảm thiểu các URL không cần thiết. Những thay đổi nhỏ trong cách quản lý crawl budget có thể tạo ra sự khác biệt lớn trong khả năng index và cuối cùng là hiệu suất SEO tổng thể.
Hãy nhớ rằng crawl budget không phải là mục tiêu cuối cùng mà là công cụ để đạt được mục tiêu: nội dung chất lượng được index nhanh chóng và tiếp cận đúng người dùng. Kết hợp tối ưu crawl budget với chiến lược nội dung mạnh mẽ và trải nghiệm người dùng tốt sẽ mang lại lợi thế cạnh tranh bền vững.
- Theme WordPress Folder Structure Là Gì? Hướng Dẫn Chi Tiết Cấu Trúc Thư Mục Theme Chuẩn
- Plugin WordPress Gây Tăng RAM: Nguyên Nhân, Cách Nhận Diện Và Giải Pháp Tối Ưu
- Theme WordPress Mobile Friendly Lỗi: Nguyên Nhân, Cách Khắc Phục và Tối Ưu Toàn Diện
- FAQ Schema Là Gì? Hướng Dẫn Chi Tiết Tối Ưu Google Dạng Câu Hỏi Thường Gặp
- WordPress SMTP TLS Error: Nguyên Nhân Và Cách Khắc Phục Chi Tiết Từ A-Z
Bài viết cùng chủ đề:
-

Search Console Insights Report Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho Người Mới
-

BigQuery Export Search Console Là Gì? Hướng Dẫn Toàn Diện Từ A Đến Z Cho SEO
-

Bulk Export GSC Là Gì? Hướng Dẫn Chi Tiết Xuất Dữ Liệu Hàng Loạt Từ Google Search Console
-

Export Data Search Console Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Để Tận Dụng Tối Đa Dữ Liệu
-

GSC API Là Gì? Hướng Dẫn Toàn Diện Từ A Đến Z Cho Người Làm SEO
-

Search Console API là gì? Hướng dẫn chi tiết từ A-Z cho SEO và Developer
-

Device Filter Là Gì? Hướng Dẫn Toàn Diện Về Bộ Lọc Thiết Bị Trong Marketing Và Bảo Mật
-
Country Filter Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Người Mới Bắt Đầu
-

Page Filter Là Gì? Hướng Dẫn Toàn Diện Từ Cơ Bản Đến Nâng Cao Cho Người Mới
-
Query Filter Là Gì? Hướng Dẫn Toàn Diện Từ Cơ Bản Đến Nâng Cao
-

Regex Filter Search Console Là Gì? Hướng Dẫn Chi Tiết Từ Cơ Bản Đến Nâng Cao Cho SEO Specialist
-
So sánh ngày trong Google Search Console (Compare Date) là gì? Hướng dẫn chi tiết A-Z cho người mới
-

Date Filter trong GSC là gì? Hướng dẫn chi tiết cách sử dụng bộ lọc ngày tháng trong Google Search Console
-

News Search Filter Là Gì? Hướng Dẫn Toàn Diện Về Bộ Lọc Tìm Kiếm Tin Tức Hiện Đại
-

Video Search Filter Là Gì? Cách Tận Dụng Bộ Lọc Tìm Kiếm Video Hiệu Quả
-

Image Search Filter là gì? Hướng dẫn Toàn Diện về Bộ Lọc Tìm Kiếm Hình Ảnh