Crawl Là Gì? Toàn Bộ Kiến Thức Từ A-Z Về Thu Thập Dữ Liệu Web
Th6
Trong thế giới công nghệ và SEO, thuật ngữ crawl xuất hiện thường xuyên như một khái niệm nền tảng. Dù bạn là chủ website, SEOer hay lập trình viên, việc hiểu đúng bản chất của crawl là gì sẽ giúp bạn kiểm soát cách công cụ tìm kiếm tương tác với nội dung của mình. Crawl, hay còn gọi là thu thập dữ liệu, là quy trình mà bot của Google, Bing hay các công cụ tìm kiếm khác tự động quét hàng tỷ trang web để tổng hợp thông tin. Hiểu rõ crawl là gì không chỉ giúp website của bạn xuất hiện trên kết quả tìm kiếm mà còn tối ưu hiệu suất và trải nghiệm người dùng.
Định Nghĩa Crawl Là Gì? Giải Thích Chi Tiết

Crawl – viết tắt của web crawling – là quá trình các chương trình tự động (thường gọi là bot, spider hoặc crawler) di chuyển qua các liên kết trên internet để thu thập dữ liệu từ các trang web. Bot bắt đầu bằng một danh sách URL có sẵn, sau đó theo các liên kết trên những trang đó để khám phá thêm nội dung mới.
Khi nói crawl là gì trong SEO, đó chính là bước đầu tiên trong chu trình hoạt động của công cụ tìm kiếm: Crawl → Index → Rank. Nếu không có crawl, công cụ tìm kiếm không thể biết được trang web của bạn tồn tại, chứ đừng nói đến việc xếp hạng.
Bản Chất Của Hoạt Động Crawl
Bản chất của crawl giống như cách một thủ thư đi dọc các kệ sách, lấy từng cuốn sách, ghi lại tên, nội dung tóm tắt và vị trí của nó. Trong thế giới số, thủ thư đó là Googlebot. Googlebot sử dụng thuật toán để quyết định tần suất crawl, độ sâu crawl và ưu tiên trang nào trước.
Crawl không phải là hành động một lần. Nó diễn ra liên tục, mỗi ngày có hàng tỷ URL được thu thập. Tốc độ crawl phụ thuộc vào nhiều yếu tố như ngân sách crawl, cấu trúc website và chất lượng nội dung.
Phân Loại Crawl Trong Thực Tế
Không phải mọi hoạt động thu thập dữ liệu đều giống nhau. Dựa vào mục đích và phạm vi, chúng ta có thể phân chia thành các loại crawl chính sau đây.
Crawl Của Công Cụ Tìm Kiếm
Đây là loại phổ biến nhất. Googlebot, Bingbot, Yandex Bot… là các crawler do các công ty công nghệ vận hành. Chúng thu thập dữ liệu để xây dựng chỉ mục tìm kiếm. Mục tiêu là hiểu nội dung trang web và đánh giá mức độ liên quan với các truy vấn của người dùng.
Crawl Dữ Liệu Cho Phân Tích (Data Crawling)
Các nhà nghiên cứu, marketer hoặc lập trình viên cũng sử dụng crawl để thu thập thông tin từ website cho mục đích phân tích thị trường, giám sát giá cả, nghiên cứu đối thủ. Loại này thường được thực hiện bằng các công cụ như Scrapy, BeautifulSoup, Apache Nutch.
Crawl Nội Bộ (Internal Crawl)
Một số hệ thống quản lý nội dung hoặc ứng dụng doanh nghiệp sử dụng crawler nội bộ để đồng bộ dữ liệu, kiểm tra liên kết hỏng hoặc xây dựng sơ đồ trang. Khác với crawl công cộng, các crawler này hoạt động trong môi trường mạng riêng.
Quy Trình Crawl Hoạt Động Như Thế Nào?

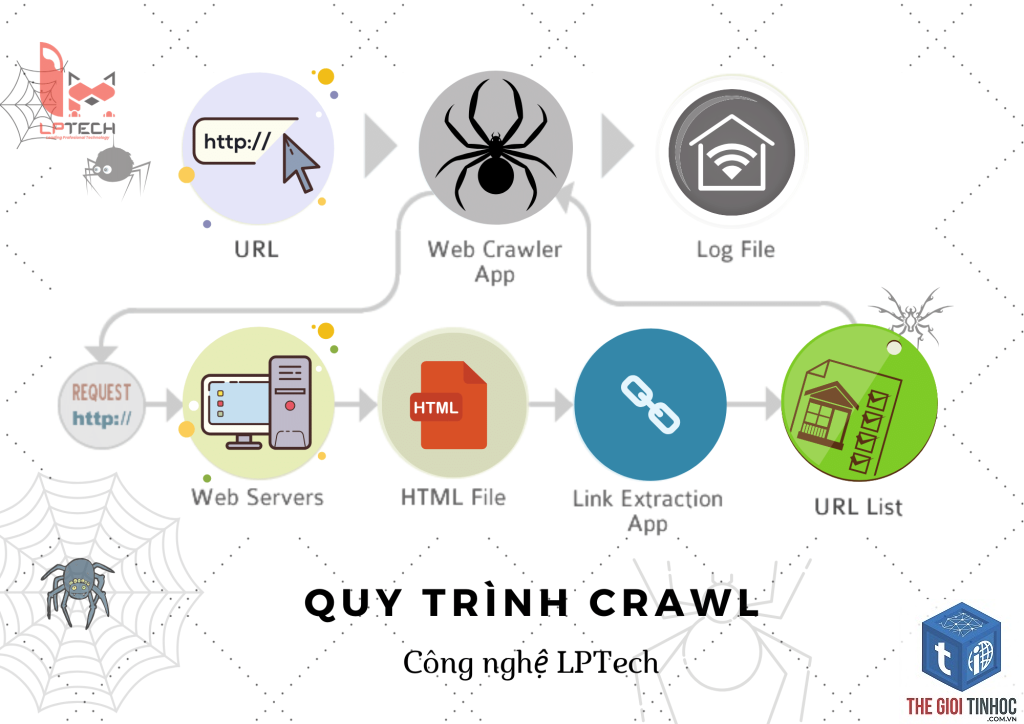
Để hiểu sâu về crawl là gì, bạn cần nắm được quy trình từ lúc bot bắt đầu cho đến khi dữ liệu được lưu trữ.
- Khởi tạo danh sách URL gốc (Seed URLs): Bot bắt đầu từ một tập hợp các URL đã biết, thường từ những website uy tín, sitemap hoặc lịch sử crawl cũ.
- Tải trang và phân tích: Bot gửi yêu cầu HTTP đến máy chủ, tải nội dung HTML, CSS, JavaScript. Sau đó phân tích để trích xuất văn bản và các liên kết.
- Trích xuất liên kết (Extract links): Từ trang hiện tại, bot phát hiện tất cả các thẻ và thêm chúng vào hàng đợi URL cần crawl tiếp theo.
- Kiểm tra trùng lặp và chuẩn hóa URL: Bot lọc các URL đã crawl, xử lý tham số, loại bỏ URL trùng để tránh lãng phí tài nguyên.
- Lập lịch crawl (Scheduling): Dựa vào mức độ ưu tiên, tần suất cập nhật, bot quyết định thời điểm crawl lại trang đó.
- Lưu trữ dữ liệu: Nội dung sau khi thu thập được chuyển đến hệ thống index để xử lý và phân tích tiếp theo.
Crawl Index Và Render – Sự Khác Biệt Quan Trọng
Nhiều người nhầm lẫn giữa crawl, index và render. Đây là ba bước riêng biệt trong quy trình xử lý của công cụ tìm kiếm.
| Thuật ngữ | Mô tả | Ví dụ |
|---|---|---|
| Crawl | Quá trình bot ghé thăm và tải nội dung trang web | Googlebot truy cập URL example.com và tải file HTML |
| Index | Quá trình phân tích và lưu trữ nội dung vào cơ sở dữ liệu tìm kiếm | Nội dung được thêm vào index của Google, sẵn sàng hiển thị khi ai đó tìm kiếm |
| Render | Quá trình thực thi JavaScript để hiển thị đầy đủ nội dung động | Googlebot chạy code React để thấy các phần tử được tạo bằng JS |
Một trang có thể được crawl nhưng không được index nếu nội dung trùng lặp hoặc chất lượng thấp. Render đặc biệt quan trọng với các website SPA (Single Page Application).
Lợi Ích Và Hạn Chế Của Hoạt Động Crawl

Lợi ích khi crawl hoạt động hiệu quả
- Phát hiện nội dung mới nhanh chóng, giúp website xuất hiện trong kết quả tìm kiếm sớm nhất.
- Giúp công cụ tìm kiếm cập nhật những thay đổi trên trang (nội dung mới, sản phẩm mới, bài viết mới).
- Hỗ trợ phát hiện và sửa lỗi kỹ thuật như liên kết hỏng, lỗi 404.
- Cải thiện khả năng hiển thị tổng thể của website trên các công cụ tìm kiếm.
Hạn chế và thách thức
- Ngân sách crawl có hạn: Bot chỉ có một lượng tài nguyên nhất định để crawl website của bạn. Nếu quá nhiều trang không quan trọng bị crawl, các trang quan trọng có thể bị bỏ qua.
- Tải lên máy chủ: Nếu tốc độ crawl quá cao, máy chủ có thể bị quá tải, làm chậm website thật.
- Không crawl được nội dung JavaScript phức tạp: Nếu render không thành công, nội dung động sẽ bị bỏ sót.
- Crawl mất kiểm soát: Các bot không mong muốn (như bot xấu) có thể crawl gây hao tổn băng thông.
So Sánh Crawl Và Scraping: Hai Khái Niệm Dễ Gây Nhầm Lẫn
Nhiều người thường hỏi liệu crawl là gì có giống với web scraping hay không. Thực chất, crawl và scraping có điểm chung nhưng khác nhau về mục tiêu và phạm vi.
| Tiêu chí | Crawl (Thu thập dữ liệu) | Scraping (Trích xuất dữ liệu) |
|---|---|---|
| Mục đích | Khám phá và thu thập hàng loạt URL | Trích xuất dữ liệu cụ thể từ một trang (giá, mô tả) |
| Quy mô | Toàn bộ website hoặc nhiều website | Thường giới hạn trong một số trang nhất định |
| Kết quả | Danh sách URL đã thu thập và nội dung thô | Dữ liệu có cấu trúc (CSV, JSON, bảng) |
| Công cụ | Googlebot, Screaming Frog, DeepCrawl | BeautifulSoup, Scrapy, Octoparse |
| Ứng dụng | SEO, xây dựng chỉ mục tìm kiếm | Phân tích thị trường, giám sát giá |
Tóm lại, crawl là quá trình “đi” qua các trang, còn scraping là quá trình “lấy” dữ liệu cụ thể từ các trang đã được crawl.
Ứng Dụng Thực Tế Của Crawl Trong SEO Và Marketing

Hiểu rõ crawl là gì giúp bạn áp dụng nó vào nhiều lĩnh vực thực tế.
Tối ưu crawl budget cho website
Crawl budget là số lượng URL mà Googlebot có thể và muốn crawl trên website của bạn trong một khoảng thời gian. Để tối ưu, bạn cần đảm bảo: tốc độ tải trang nhanh, cấu trúc liên kết rõ ràng, sitemap cập nhật thường xuyên, không có quá nhiều trang trùng lặp. Những trang có giá trị thấp (trang tag, trang filter) nên được chặn trong robots.txt hoặc thêm thẻ noindex.
Kiểm tra và giám sát crawl hàng ngày
Sử dụng Google Search Console để xem báo cáo crawl. Mục “Thống kê thu thập dữ liệu” cho biết Googlebot đã gửi bao nhiêu yêu cầu, thời gian tải trung bình, kích thước trang. Nếu thấy sụt giảm đột ngột, có thể website gặp lỗi kỹ thuật hoặc bị phạt.
Phát hiện và sửa lỗi crawl
Các công cụ như Screaming Frog SEO Spider cho phép bạn mô phỏng Googlebot để crawl chính website của mình. Từ đó phát hiện liên kết hỏng, chuyển hướng sai, nội dung trùng lặp, thẻ meta thiếu. Đây là cách hiệu quả để giữ cho “sức khỏe” crawl luôn tốt.
Sai Lầm Thường Gặp Khi Quản Lý Crawl Và Cách Tránh
Trong quá trình xử lý crawl, nhiều webmaster mắc những sai lầm khiến hiệu quả SEO giảm sút.
- Chặn nhầm tài nguyên quan trọng trong robots.txt: Nhiều người vô tình chặn Googlebot truy cập file CSS, JavaScript hoặc các trang quan trọng. Hậu quả là bot không thể render đúng nội dung.
- Không tối ưu sitemap: Sitemap XML lỗi thời, chứa quá nhiều URL không quan trọng hoặc không được gửi lại sau khi cập nhật nội dung.
- Để crawl bị lãng phí vào trang 404 hoặc vòng lặc liên kết: Các trang lỗi vẫn được crawl gây tốn ngân sách, cần chuyển hướng hoặc trả về mã trạng thái phù hợp.
- Bỏ qua tối ưu tốc độ tải trang: Nếu website quá chậm, Googlebot sẽ giảm tần suất crawl vì cho rằng máy chủ không ổn định.
- Sử dụng quá nhiều tham số URL động: Các tham số như?session=123,?ref=abc tạo ra hàng ngàn URL khác nhau làm loãng crawl budget.
Lưu Ý Quan Trọng Khi Làm Việc Với Crawl

Để tận dụng tối đa lợi ích từ crawl và tránh rủi ro, bạn cần ghi nhớ những điểm sau.
- Luôn kiểm tra file robots.txt: Đảm bảo không chặn Googlebot ở những trang bạn muốn được index. Sử dụng thẻ Disallow có mục đích cụ thể.
- Theo dõi log máy chủ: Xem Googlebot có thực sự truy cập vào website không, tần suất ra sao, có gặp lỗi server không.
- Cân bằng giữa nội dung tĩnh và động: Với các trang web React, Vue, hãy đảm bảo server-side rendering (SSR) hoặc dynamic rendering để Googlebot thấy nội dung.
- Cập nhật sitemap thường xuyên: Đặc biệt khi thêm trang mới hoặc xóa trang cũ. Gửi sitemap qua Google Search Console.
- Giới hạn crawl của bot xấu: Sử dụng tệp.htaccess hoặc tường lửa để chặn các user-agent không mong muốn nhằm tiết kiệm băng thông.
Câu Hỏi Thường Gặp Về Crawl (FAQ)
Crawl là gì? Crawl có giống với index không?
Crawl là quá trình bot ghé thăm và tải nội dung trang web. Index là quá trình phân tích và lưu trữ nội dung đó vào cơ sở dữ liệu tìm kiếm. Một trang cần được crawl trước, sau đó mới có thể được index.
Làm thế nào để kiểm tra xem Googlebot có crawl website của tôi không?
Nguyên nhân có thể do máy chủ quá chậm, lỗi server, robots.txt chặn bot, hoặc website quá mới và chưa có đủ tín hiệu để Google ưu tiên crawl. Hãy tối ưu tốc độ và đảm bảo sitemap được gửi đúng cách.
Crawl budget là gì? Làm sao để tối ưu?
Crawl budget là số lần Googlebot crawl website của bạn trong một khung thời gian. Để tối ưu, hãy loại bỏ các trang chất lượng thấp, giảm số lượng URL trùng lặp, tăng tốc độ tải trang và cải thiện cấu trúc liên kết nội bộ.
Có nên chặn Googlebot crawl một số trang không?
Nên chặn những trang không mang giá trị SEO như trang admin, trang kết quả tìm kiếm nội bộ, trang có tham số không cần thiết. Tuyệt đối không chặn trang nội dung chính.
Kết Luận
Crawl là nền tảng của toàn bộ hoạt động SEO và marketing kỹ thuật số. Hiểu rõ crawl là gì, cách nó vận hành và cách tối ưu giúp bạn kiểm soát được sự hiện diện của website trên công cụ tìm kiếm. Từ việc quản lý crawl budget, sửa lỗi kỹ thuật đến áp dụng các công cụ giám sát, tất cả đều đóng vai trò quyết định đến thành công lâu dài. Hãy bắt đầu bằng việc kiểm tra robots.txt, gửi sitemap và theo dõi báo cáo crawl trong Google Search Console ngay hôm nay.
- Theme WordPress Font Awesome Lỗi: Nguyên Nhân, Cách Khắc Phục Triệt Để
- Khắc Phục Lỗi WordPress SMTP OpenSSL: Nguyên Nhân và Giải Pháp Chi Tiết
- Elementor xung đột Mailchimp: Nguyên nhân, dấu hiệu và giải pháp triệt để
- WordPress Dashboard Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Người Mới Bắt Đầu
- Cách Khắc Phục WordPress Email Webhook Lỗi: Nguyên Nhân Và Giải Pháp Chi Tiết
Bài viết cùng chủ đề:
-

Schema Validator Là Gì? Công Cụ Kiểm Tra Schema Markup Chuẩn SEO Giúp Tăng Lượt Click
-

Schema Generator Là Gì? Công Cụ Tạo Dữ Liệu Cấu Trúc Tối Ưu SEO Website
-

Công Cụ Rich Result Test Hướng Dẫn Chi Tiết Từ A Đến Z Cho Người Làm SEO
-
Schema Validation Là Gì? Toàn Tập Về Xác Thực Cấu Trúc Dữ Liệu Từ Cơ Bản Đến Nâng Cao
-
Speakable Schema là gì? Cách triển khai Schema Markup giúp nội dung được Google Assistant đọc to
-
Howto Schema Là Gì? Bí Quyết Tối Ưu Nội Dung Hướng Dẫn Trong Tìm Kiếm
-

Event Schema Là Gì? Bí Quyết Đánh Bại Đối Thủ Trên Google Với Dữ Liệu Có Cấu Trúc Cho Sự Kiện
-

Service Schema là gì? Hướng dẫn chi tiết từ A đến Z để tối ưu SEO
-

Product Schema Là Gì? Bí Quyết Tối Ưu Hóa Dữ Liệu Sản Phẩm Cho Công Cụ Tìm Kiếm
-

Image Schema Là Gì? Khám Phá Toàn Diện Về Cấu Trúc Nhận Thức Nền Tảng
-

Video Schema Là Gì? Hướng Dẫn Chi Tiết Tối Ưu Video SEO Cho Website
-
WebPage Schema Là Gì? Toàn Tập Hướng Dẫn Chi Tiết Cho Người Làm SEO
-

Website Schema Là Gì? Hướng Dẫn Chi Tiết Từ A-Z Cho Người Mới Bắt Đầu
-
Person Schema Là Gì? Hướng Dẫn Chi Tiết Cách Triển Khai Schema Markup Cho Con Người
-
Organization Schema Là Gì? Hướng Dẫn Chi Tiết Triển Khai Structured Data Cho Doanh Nghiệp
-

NewsArticle Schema Là Gì? Hướng Dẫn Toàn Diện Từ A-Z Cho Website Tin Tức